Generative AI models represent one of the most disruptive shifts to the way we build applications since the advent of cloud computing. With a basic API call, software engineers can harness some of the most powerful models ever conceived, delivering capabilities that would have previously taken teams of data scientists and AI practitioners months to deliver.
At Sapphire Ventures, we feel fortunate to learn from and partner with some of the best builders of enterprise technology across both the startup ecosystem and our network of CXOs at G2K companies. We believe this seat affords us the ability to observe trends in both what companies are building, as well as how they are building products and services, giving us unique insight into emerging design patterns across companies working with different resources, corporate objectives and constraints.
This piece is the result of dozens of expert interviews, 1-on-1 discussions with technical leaders, company presentations and countless hours of independent research, and codifies our current understanding of the emerging Generative AI Application Infrastructure Stack. We share it in the spirit of learning in public and in the hopes that it imparts helpful insights to those building the next wave of innovative AI capabilities.
Before we dive into the specifics of the categories that comprise our GenAI App Infra Stack market map, we will first explore the reasons for the rapid acceleration of GenAI adoption by companies and some of the myriad challenges they face as they begin to build with this technology.
If you prefer to jump straight to our market map, click here to access it directly.
Sign up for our newsletter
What Factors Are Driving the Surge in GenAI Adoption?
AI tops the list of C-suite priorities – A broad selection of CXO surveys from the past year have had a consistent refrain—AI/ML is now at the very top of the C-suite agenda. A recent survey of top executives by BCG found 85% of executives plan to increase their spending on AI and GenAI, and multiple CIO surveys from leading investment banks listed AI/ML as the top spending priority for the coming year. This degree of attention from the highest levels of company leadership is translating into more budget for AI initiatives, as well as a shift in mindset from experimentation to production as executives raise expectations around value creation.
Early proof points are emerging across functions and industries – Code Assistance has been the most prevalent GenAI use case since the launch of GitHub Copilot in October 2021, and adoption is only accelerating, with one recent survey finding that 81% of global developers now use GenAI-powered coding assistants, nearly double six months prior. However, examples of impact are emerging beyond engineering teams with use cases across sales, marketing, customer service, legal and HR taking off, to name just a few. The impact can be significant, as evidenced in Klarna’s disclosure that they had replaced the equivalent of 700 full time customer service agents with an AI assistant built on OpenAI’s technology, driving $40M in profit improvement for the year.
Foundation models are accelerating along four critical dimensions
- Performance – While still imperfect, foundational models have advanced at a rapid pace over the last several years, resulting in significantly enhanced code, text, image, audio and video generation abilities, as well as better reasoning skills. In just the last few weeks, OpenAI’s GPT-4o release demonstrated multi-modality and reduced latency, while Google’s Gemini’s 1.5 Pro model expanded the context window to 2 million tokens, further advancing the competitive frontier on three important dimensions. The state-of-the-art in AI is being reset almost monthly, prompting AI researchers to race to create new benchmarks to keep pace with performance improvements, all while expanding the design space of what is possible for developers.
- Optionality – OpenAI’s release of GPT-4 in March 2023 was a watershed moment for GenAI and the model set the bar for performance for nearly a full year after release. However, there are several GPT-4 class models in the market today, with Anthropic’s Claude 3 Opus, and Google’s Gemini 1.5 Pro and Gemini Ultra serving as the most directly comparable closed-source offerings, while Meta’s Llama-3 and Mistral’s Mixtral 8x22B are rapidly closing the gap for open-source alternatives. With many other companies releasing models and the leading providers increasingly offering multiple sizes of models to ensure broader coverage of use cases and points along the performance vs. price tradeoff curve, builders now have unprecedented flexibility and choice.
- Accessibility – Today, developers have their choice of accessing model capabilities via 1) API directly from the model providers themselves, 2) Model-as-a-Service offerings from the major cloud providers (e.g., Google offers access to 150+ models on GCP), or 3) direct download off a public model repository like Hugging Face. Each approach has tradeoffs, and the use case, budget and technical capabilities of the team should be considered in selecting the appropriate path. However, the net impact of increased access is more experimentation, faster development cycles and downward price pressure industry wide.
- Price – Prices have significantly declined across the board in 2024 both on new and existing models. In the U.S., model providers including OpenAI and Anthropic have dropped prices across their existing and new models by more than half over the past year. In China, a brewing price war among some of the country’s biggest tech companies—including Tencent, Alibaba and Baidu—has seen price cuts of 90%+ on many of these vendors’ SOTA models and a growing number of free “lite” LLMs.
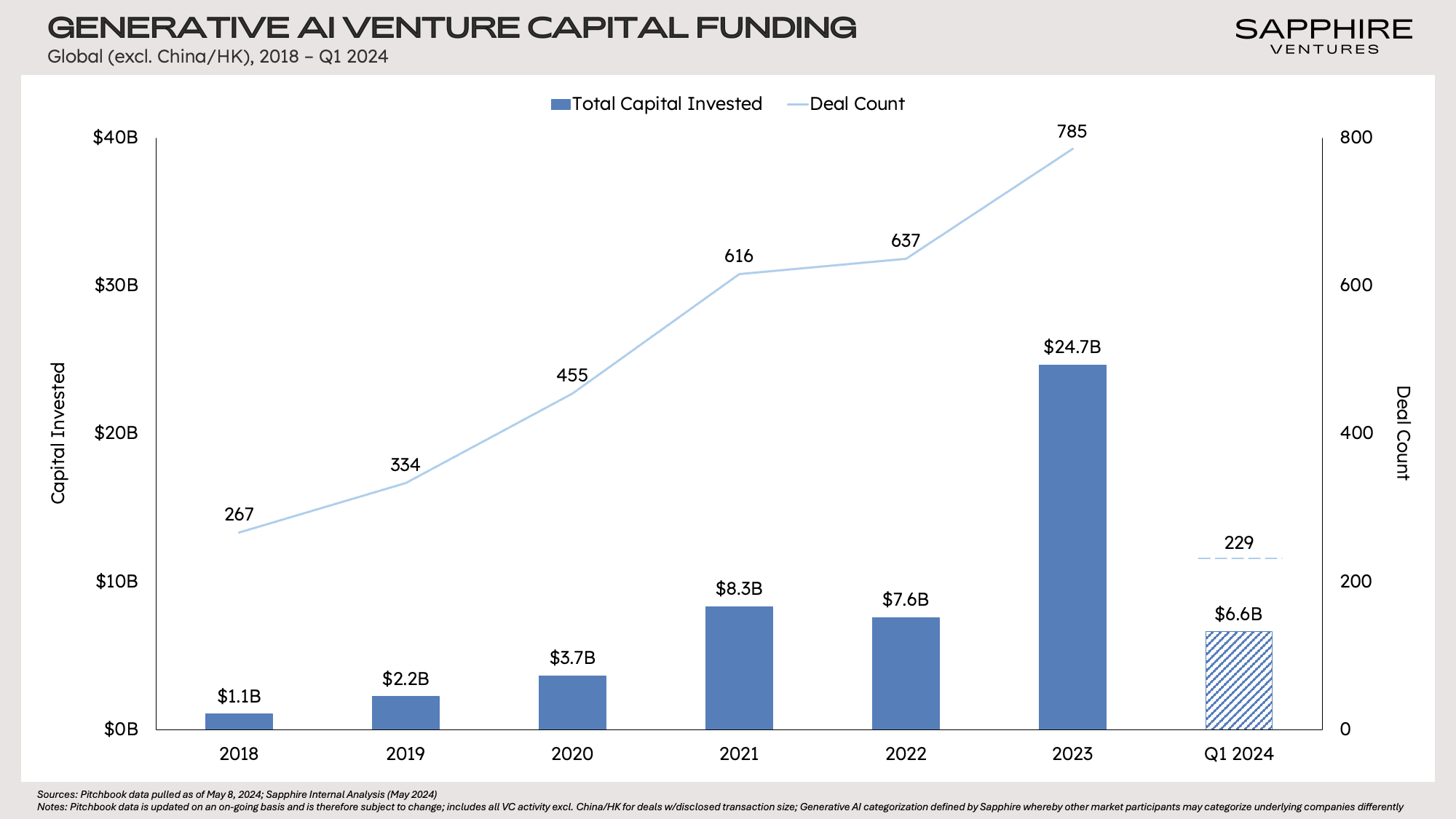
Given these dynamics, investment in AI continues to increase at a rapid pace. The largest public cloud companies are now expected to spend ~$175B in 2024 to build out AI data centers (Morgan Stanley), while VC investors poured another $7B in GenAI native companies in Q1 2024 after a record $25B was put to work in 2023. This money will lead to better infrastructure, models, tools and applications—keeping GenAI firmly in focus on corporate boardrooms for the foreseeable future.
What Are the Challenges for Enterprises Related to Building with GenAI?
Despite the incredible amount of innovation, attention and investment described above, we are still in the earliest stages of actual deployment of GenAI. According to Morgan Stanley’s most recent CIO survey, over half of enterprises (53%) do not expect to have an initial GenAI use case in production until 2025 or later, a sentiment echoed in IBM’s global study of 3K CEOs published in mid-May, which found that 71% of organizations are no further than piloting GenAI projects. Why is this the case?
The simple truth is that working with GenAI models is still very difficult. There is no instruction manual and best practices are still undefined. Models are non-deterministic and therefore unpredictable, exhibiting emergent behaviors that can amaze, as well as hallucinations that can annoy, mislead or offend. Things that work in tightly scoped proof-of-concepts break down as they are scaled up to production, and the room for error when processing real-world data and providing users with outputs is small. Furthermore, models are difficult to evaluate, given the complexity and subjectivity inherent in many outputs, diversity of use cases, still– evolving benchmarks and propensity for model drift. Finally, experienced talent is scarce (and often very expensive!), leading many organizations to attempt to reskill existing engineers on the fly to address near-term development efforts.
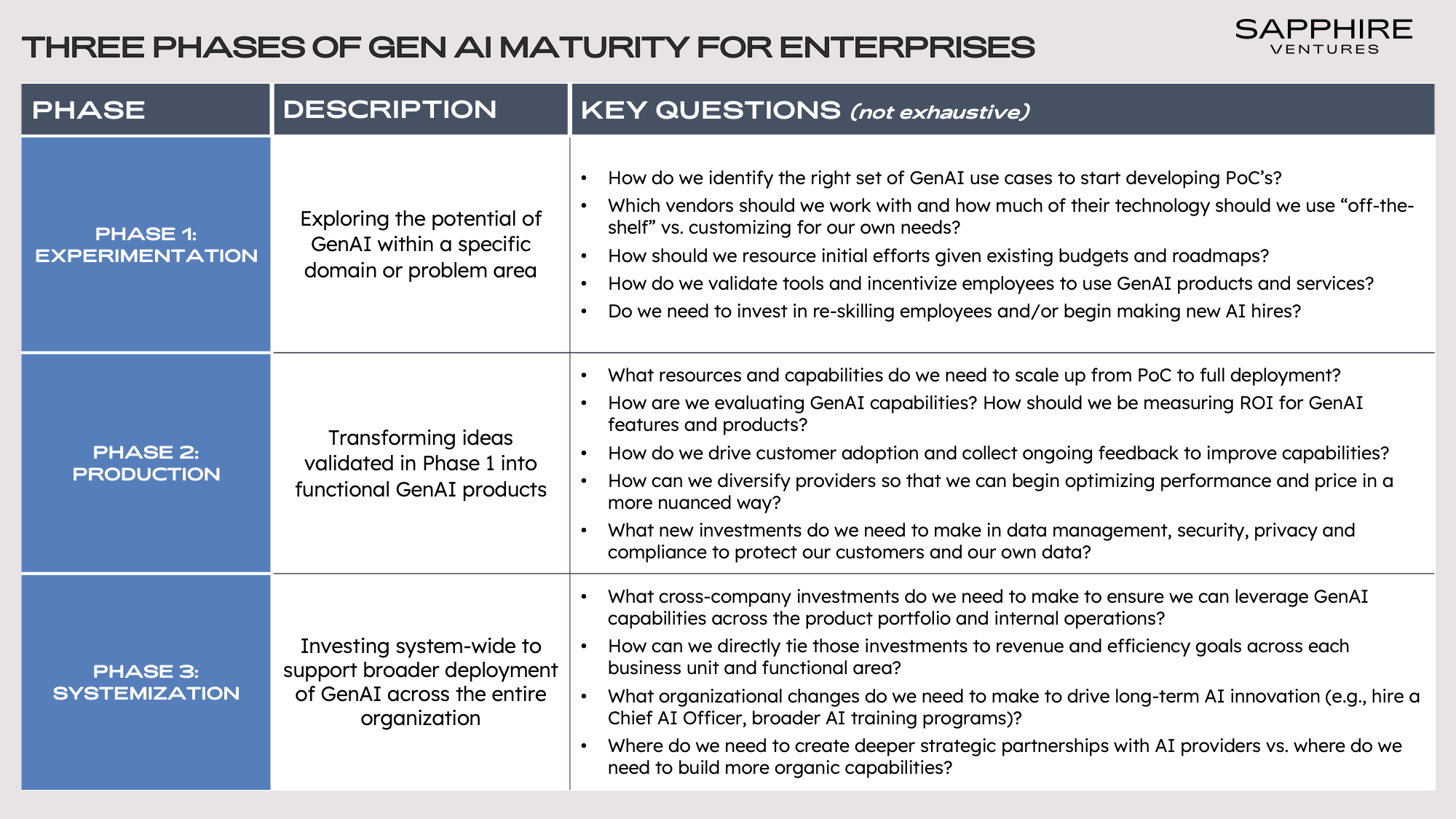
Given these challenges, it should not be surprising that many companies have been taking their time. As we consider where companies are in their GenAI maturity, we have begun using a simple three– phase Experimentation – Production – Systemization framework.
Today, the overwhelming majority of companies exist somewhere in Phase 1 or 2. As companies progress from one phase to the next, the challenges they face change, along with the tools they use and the investments they need to make. In particular, as companies move deeper into Phase 2 and begin to plan for Phase 3, they need to become more sophisticated by combining the novel techniques and tools proving effective in wrangling GenAI models with traditional software development practices (e.g., versioning, quality checks, feedback loops).
This dynamic has facilitated the rise of a new role, which the Latent Space team aptly coined the “AI Engineer.” We believe this role, which blends full stack engineering with aspects of MLOps and data engineering, is an increasingly critical one, responsible for orchestrating chains and building workflows that “sit above” the foundational model APIs.

Image credit: Latent Space
Sapphire Ventures’ View of the GenAI App Infrastructure Stack
In response to the market conditions described above, an entire ecosystem of new tools and associated startups has rapidly emerged, creating an environment that can be difficult to navigate as decision makers consider questions of build vs. buy, platform vs. best-of-breed and incumbent vs. startups.
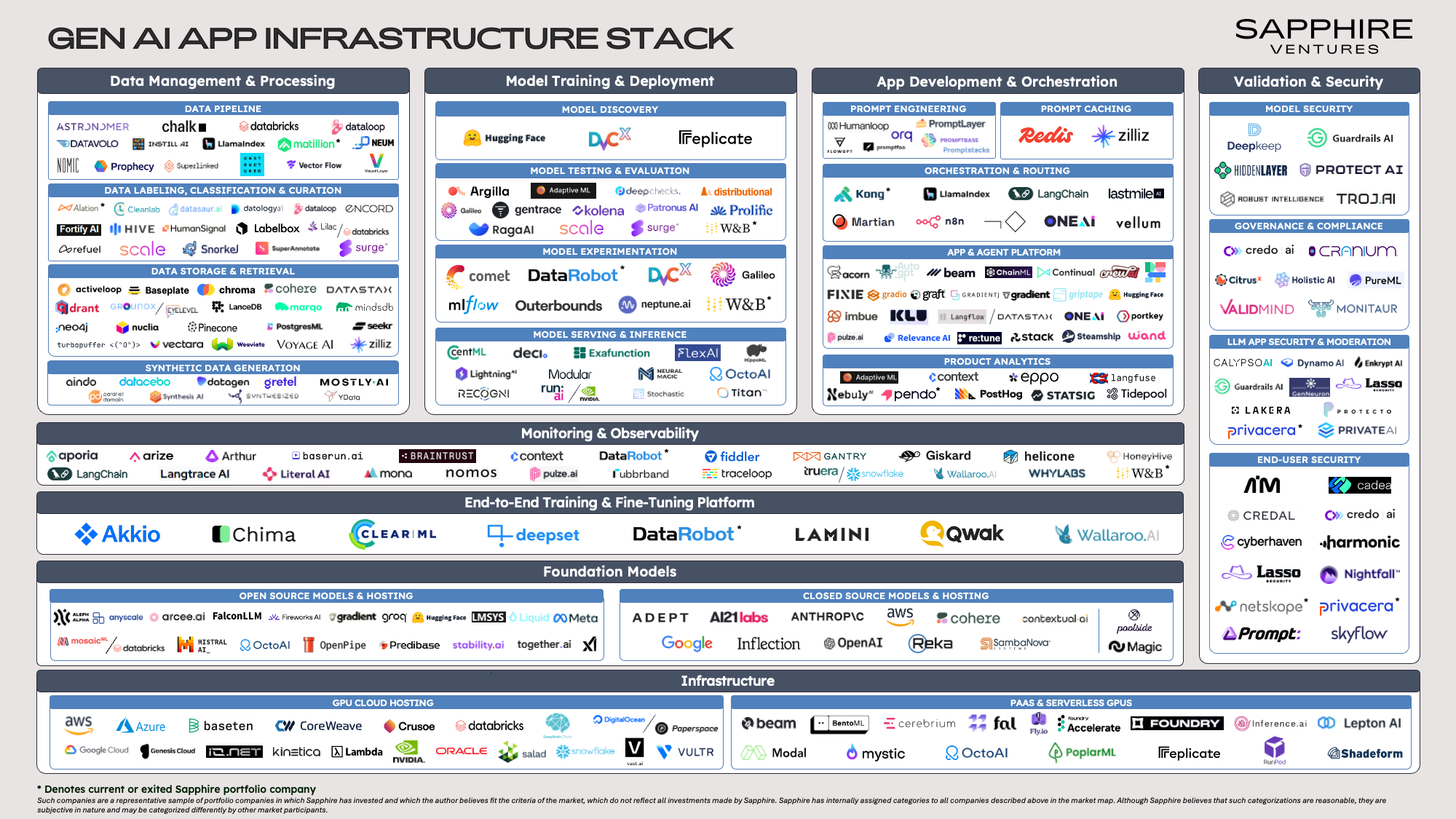
This GenAI App Infrastructure Stack market map is a guide for builders, providing a comprehensive view of the functional domains, both above and below the foundational model API line and associated startups that are starting to define this new application pattern.
We have sorted companies into groupings based on initial and/or historical market focus but note that—especially given the speed of innovation in this space—providers are expanding their product portfolios rapidly and, in some instances, could be represented in multiple areas.
Infrastructure
Infrastructure covers a broad range of categories, and effectively addressing them all would require another dedicated blog. For this piece, we focus on GPU-enabled compute, as the dividing line between the GPU rich and GPU poor has emerged as one of the critical determinants of success in the initial wave of GenAI development. Given the compute– intensive profile of GenAI workloads, which require substantial processing power and memory to handle model training, bursty fine-tuning runs and ongoing inference, GPUs—whose architecture excels at parallel processing multiple operations simultaneously—are uniquely well-suited.
NVIDIA, who first developed GPUs for video gaming in the 1990s, is estimated to currently own 96% of the overall GPU market (Macquarie Research) and has been the primary beneficiary of the insatiable GPU demand that has existed since the middle of 2022. Wait times for their leading-edge chips at one point stretched to over a year and, given the company’s market position, they have essentially been able to dictate product access to their customers, which include all of the hyperscalers (e.g., Microsoft is reportedly looking to 3x their current supply of 500K-600K GPUs to 1.8M by the end of the year) and most of the world’s largest technology companies (e.g., Meta recently claimed to have 350K NVIDIA H100 GPUs.)
In this supply–constrained environment, players of all types are racing to build GPU-alternative chip options or provide access to NVIDIA’s GPU capabilities via new delivery models. At the chip layer, this has manifested in the form of:
- New GPU offerings (like those from AMD and Cerebras)
- AI ASICs from hyperscalers (like TPUs from Google, Inferentia chips from Amazon and Maia 100’s from Microsoft)
- New chip architectures designed specifically for LLM inference (like those from Etched and Groq)
- Compilers and runtimes that both enable consumption of heterogenous GPU stacks and unlock “GPU-like” performance on traditional CPUs (such as Modular and Neural Magic)
- Various inference optimization libraries and techniques (such as CentML and OctoAI)
On the GPU access side, we have also seen a proliferation of cloud-based models designed to give smaller players access to the kind of massive GPU clusters major tech companies have been able to procure. We have highlighted two types of these emerging cloud providers in our market map above, both focused specifically on hosting AI workloads.
Sub-Category Definitions
- GPU Cloud Hosting platforms provide access to persistent GPU capacity hosted on cloud virtual machines. These cloud providers enable teams to easily scale GPU resources up or down based on their needs without needing to invest in physical hardware and to overcome potential inventory shortages and concentration risks posed by a sole-provider strategy. Providers in this space include both incumbent hyperscalers (such as GCP) and boutique GPU clouds such as CoreWeave, Lambda Labs, Genesis Cloud and Crusoe. Some of these “boutique” players have significant scale, for instance, CoreWeave is reportedly projecting $2B+ in 2024 revenue.
- PaaS & Serverless GPUs platforms enable more flexible consumption of GPUs in the form of per-second, pay-as-you-go billing. Many providers in this space offer additional value-add services to support the full lifecycle of model hosting including networking, web endpoints, scheduling, optimized serving frameworks and even pre-trained and optimized base open models which customers can consume and further pre-train off-the-shelf. Notable companies here include OctoAI, Replicate, Beam, RunPod, Baseten, Lepton and Modal.
Foundation Models
As mentioned above, dramatic increases in both the capabilities and accessibility of pre-trained foundational models, designed to be applied out-of-the-box across a variety of use cases, have vastly simplified the process of getting GenAI use cases into production.
Additional trends we are tracking relevant to builders in this space include:
A Growing Focus on Efficiency
Initially, foundation model providers were almost solely focused on maximizing model performance via brute force scale. However, there is a growing recognition that smaller models can adequately meet many enterprise needs (and may be required for most use cases at the edge) while offering lower latency and reduced costs. Model developers have begun releasing different sizes of models to allow end-users to easily choose between price vs. performance (see Claude’s recent release of their three-tiered model family for an example) and ramped up experimentation with small language models (see Apple’s recent release of the OpenELM model family and Microsoft’s competing Phi-3 family).
Continued Innovation in Model Architectures
The transformer architecture released the current wave of innovation in GenAI, largely replacing other architectures like convolution neural networks (CNNs) and recurrent neural networks (RNNs) along the way. Today, model researchers have begun to enhance these transformer models by introducing layers of specialization and ensemble learning to handle increasingly complex tasks. One of the most popular of these “meta-architectures” is the mixture of experts (MoEs) approach, which involves incorporating various specialized sub-models (the “experts”) into a larger transformer architecture, where the experts can themselves be smaller transformer models. This approach not only permits scaling up models or datasets within the same compute budget but also reduces inference costs by using fewer parameters per token. (For instance, Mistral’s recent Mixtral 8x22B is a MoE which effectively uses only 39B out of its total 141B parameters per token, akin to other notable MoEs like OpenAI’s GPT-4 and Google’s Gemini 1.5.)
Sub-Category Definitions
- Open-Source Models provide publicly accessible GenAI model architectures, weights and/or training data. Proponents of open-source offerings aim to foster community collaboration, transparency and innovation by allowing anyone to use, modify and distribute these models. Notable companies here include Meta, Mistral AI, xAI and Aleph Alpha.
- Open-Source Hosting platforms offer easy access to open-source models for training, fine-tuning and inference, often through pay per token consumption. Notable companies here include Hugging Face, Anyscale, Groq, MosaicML / Databricks and Arcee AI.
- Closed-Source Models & Hosting solutions are proprietary GenAI models and platforms where the source code, model architectures and weights are not publicly disclosed or shared. These solutions offer exclusive access to their GenAI models, often with a focus on providing tailored, secure and scalable services. Notable companies here include OpenAI / Microsoft, Google, Anthropic, Cohere, Reka, Magic and Poolside.
Data Management & Processing
Access to clean, relevant data is key for every stage of development when building a GenAI application—from training through inference. Traditional DataOps is more imperative than ever; however, when working with GenAI, the scope increases to include unstructured and labeled datasets, synthetic data and embeddings/vectors. Though companies may use existing data management solutions for some of these, they may also need to adopt specialized tools.
A couple of the dynamics we are tracking in this space include:
The Evolution of Grounding Techniques
Grounding a GenAI model involves using specific strategies to ensure a model’s responses are contextually and factually accurate by anchoring them to real-world knowledge or specific data sources, thus improving the quality of responses and reducing hallucinations. The two primary methods for grounding models today are Retrieval Augmented Generation (RAG) and fine-tuning. Practitioners continue to debate when to use each technique and how to implement them. Of the two, in our conversations with builders, RAG workflows appear to be gaining ground. However, these same developers report using a broad range of embedding models, vector databases, graph databases and vector search capabilities in execution, suggesting that there will be multiple RAG reference designs for companies to consider and that the default solution providers underpinning the workflows have yet to be cemented. We are also closely watching the traction of RAG-as-a-service offerings from companies like Vectara and Nuclia, which make RAG accessible to less technical users.
While RAG has been on the rise, fine-tuning, which requires adjusting pre-trained model parameters and extending training on specifically curated datasets, seems to have receded somewhat in our conversations. As model capabilities have advanced and RAG workflows have become easier to build, many companies see less value in investing the extra time, effort and cost to fine–tune models. However, we often observe sophisticated builders utilizing both fine-tuning and RAG as they optimize for specific use cases—with one strategy being the fine–tuning of smaller models to support a smaller set of differentiated application capabilities critical to the user experience. Ultimately, we view the debate here as an “and” vs. an “or” proposition.
Finally, while context windows are not traditionally seen as a grounding technique, the rapid growth in the size of context windows over the last few months—led by Google, which just announced the first 2 million token window for their Gemini 1.5 Pro model—has stoked debate around whether RAG or fine-tuning will be necessary in a future where accommodating near–infinite input may be possible. We believe that developers will likely adopt a combination of these approaches, as well as new techniques that will surely emerge, to integrate proprietary data and real-time external inputs in a scalable way.
The Increasing Use of Synthetic Data
Synthetic data is a growing area of research in GenAI as the demand for model training data increases and traditional sources like the web are being exhausted many unanswered questions about synthetic data’s impact on model performance and bias. Early research indicates that successive generations of models trained on increasing proportions of synthetic data experience a progressive decline in quality and diversity. However, models trained on fresh real-world data with a smaller portion of synthetic data (like Google’s recent approach with Gemma) showed boosted performance.
Sub-Category Definitions
- Data Pipeline solutions orchestrate the ingestion, transformation and organization of raw structured and unstructured data into a format that can be run through a GenAI model, either in batches or real-time. A data pipeline can be constructed via a single platform, or a series of modularized components linked together by an orchestration framework. Notable companies here include Matillion (a Sapphire Ventures portfolio company), Unstructured, Chalk, Datavolo and Nomic.
- Data Labeling, Classification & Curation solutions annotate raw data with meaningful tags or labels to provide context for a model during training, fine-tuning or inference. Data labeling is one of the more mature sub-categories on our market map, with multiple vendors in the space commanding $1B+ valuations. Though labeling was traditionally a fully manual process, improved tooling, including the development of models that can handle certain types of data labelling, has led to a rise in semi- or fully automated labeling. As a result of the competitive threat of automation, most of the data labeling platforms have added additional upstream or downstream data management capabilities. Notable companies here include Scale, Hive, Snorkel, SuperAnnotate and Alation (a Sapphire Ventures portfolio company).
- Data Storage & Retrieval solutions efficiently store and retrieve data and GenAI model artifacts to facilitate training, fine-tuning and in-context learning. VectorDBs are a common storage solution used here as they can handle multi-dimensional arrays (or vectors) that represent complex data such as images, text or audio. The vectorDB category has become increasingly crowded over the past year as many incumbents have added vector support in response to both customer demand and the growing number of vectorDB startups that have raised venture funding. Another, more legacy, storage modality that has proven to be well-suited for GenAI use cases is graphDBs, which are designed to efficiently store entities (nodes) and their relationships (edges). The structure of graphDBs makes them especially well-suited for use cases related to recommendation systems and social networks where relationships between data points are as important as the data points themselves. Notable vectorDB companies include Pinecone, Weaviate, Qdrant, Milvus/Zilliz and Chroma. Notable graphDBs companies include Neo4j, TigerGraph and DataStax.
- Synthetic Data Generation solutions produce artificial data via algorithms or simulations. This synthetic data can be used alongside, or in specific cases, replace real-world data when that data is too sensitive, incomplete, imbalanced and/or difficult to acquire. As data needs for training foundation models continues to exhaust existing web and public datasets, we expect the importance of synthetic data to grow. Notable companies here include Datagen, Gretel, Ydata, Datacebo and Parallel Domain.
Model Training & Deployment
In early 2023, there was still a lot of debate about working with pre-trained models vs. training models from scratch. However, as the leading foundational models continued to advance throughout the year, evidence began to mount that these models could beat specialized models even within their own domains. Most notably, GPT-4’s triumph over BloombergGPT on almost all finance tasks, even without any finance specific training or fine-tuning, served as an impressive demonstration of the models’ capabilities, as well as a cautionary tale for others considering building from the ground up. Today, only a very small percentage of enterprises create their own custom models. We expect this practice to become even rarer for enterprises in the future, except perhaps in incredibly technical domains (e.g., biotech, life sciences).
Instead, in 2024, we think of “training” and deploying a GenAI model as a function of optimizing end-to-end workflows for model (or models) selection, customization (see “Data Management & Processing), ongoing testing and evaluation, experimentation and production.
Sub-Category Definitions
- Model Discovery services consist primarily of centralized repositories for finding, sharing and deploying pre-trained GenAI models and datasets to promote collaboration and accelerate development by making GenAI models more accessible. Notable companies here include Hugging Face, DVC and Replicate.
- Model Testing & Evaluation solutions aim to guide, correct and validate the learning of GenAI models, which can be a significant task given the challenges of working with foundation models described above. Several universities and research organizations have launched benchmarking projects aimed at improving the transparency of foundation models (including MMLU and HELM). Despite these efforts, there is little consensus on standards and the rapid improvement in model capabilities renders the benchmarks that do exist quickly outdated. From our conversations, many enterprises are instead turning to custom validation and benchmarking tools, though adoption across this sub-category is early. Notable companies here include Weights & Biases (a Sapphire Ventures portfolio company), Deepchecks, Distributional, RagaAI, Patronus AI and Argilla.
- Model Experimentation solutions record, organize and analyze information related to experiments (such as training strategies, changing hyperparameters, etc.). These tools allow AI teams to maintain detailed records of their experiments so they can better understand outcomes, iterate on the experiments to produce different results and reproduce previous experiments. This is important even for customization strategies such as RAG. Notable companies here include Weights & Biases (a Sapphire Ventures portfolio company), DataRobot (a Sapphire Ventures portfolio company), Neptune.ai, Galileo and CometML.
- Model Serving & Inference solutions enhance the speed or efficiency of GenAI models during their inference phase via a range of possible optimizations, including pruning, parallelism, quantization, knowledge distillation, batching and offloading. Notable companies here include Run:AI/NVIDIA, LightningAI, CentML, Exafunction and TitanML.
App Development & Orchestration
This category is expansive and one of the fastest moving on our market map as start-ups race to develop the tooling enterprises need to better interact with and link up foundation models to build solutions which can address more complex workflows rather than just delivering narrow AI features.
Trends we are keeping a close eye on across App Development & Orchestration include:
Prompt Engineering Remains a Crucial (and Complex) Skill
Precise and well–formatted prompts, enriched with relevant contextual data, strongly influence the quality of model outputs, in a manner that still often surprises both developers and end-users. Despite initial skepticism about the long-term prospects of prompting, and the emerging profession of prompt engineering specifically, companies continue to seek, and pay handsomely, employees with demonstrated prompt engineering skills. We believe this trend will persist and will be further supported by emerging services that can help companies craft, store, test, manage and update prompts (see below).
Agents Are Here, but Very Early
Agents can enable a model (or a series of models) to complete an action, or series of actions, on a user’s behalf with little to no intervention. Agentic workflows promise to expand the ways in which models can be utilized and enable builders to optimize each step individually, potentially allowing for significant productivity gains. Today, truly autonomous agents are not yet a reality, but we observe a growing number of services that are helping users build lightweight, custom assistants capable of tackling tasks like more complex engineering workflows (beyond just code assistance), extracting and summarizing information from multiple sources, auto-tagging data and more.
Sub-Category Definitions
- Prompt Engineering solutions craft and refine GenAI model inputs and prompts to effectively guide the model’s response in a desired direction, as the specificity and nuance of prompts can significantly impact the quality and relevance of outputs from even the most advanced models. Features like prompt playgrounds provide an interactive environment where users can experiment with and refine prompts, reducing the trial and error typically required by offering real-time feedback on how different prompts affect outputs. This also helps builders quickly understand the model’s input processing and develop more effective prompts without requiring the same deep technical knowledge of the model’s internals. Notable companies here include Orq, PromptBase, Humanloop, FlowGPT and PromptLayer.
- Prompt Caching solutions help maintain consistency and scalability by storing effective prompts and their responses, allowing for reuse across similar queries and different model versions, thus reducing costs and mitigating issues related to model updates and the need for continuous re-engineering of prompts as context windows and model capabilities evolve. Notable companies here include Redis and Zilliz.
- Orchestration frameworks provide a common abstraction for building reusable components that can execute multi-staged transactions. They often include out-of-the-box model integrations, prompt templates, document loaders and splitters, a memory store, integrations with 3rd party applications and support for other programming primitives (e.g., asynchronous calls, retries, fallbacks, etc.). Prompt routers facilitate testing and usage of multiple model families and versions, intelligently selecting the appropriate model engine based on use case, accuracy, latency and cost. Notable companies here include LlamaIndex, Langchain, Martian and OneAI.
- App & Agent Platforms provide a simpler interface to leverage foundation models and other tools to build purpose-built AI assistants that can perform a variety of tasks. Ultimately, they aim to allow users to easily create fully autonomous agents capable of reasoning through higher-order directives, compiling task lists, determining an appropriate order for tasks and fully executing a task on behalf of an end-user. Hosting Platforms serve as next-gen PaaS for hosting LLM applications. They provide the turn-key components necessary for deploying and operating an LLM application including infrastructure resources, vector storage, key management, the ability to handle and segment multi-tenant contexts, execute async tasks and more. Notable companies here include Imbue, Gradient, Klu, Steamship and Dust.
- Product Analytics solutions move beyond the traditional thumbs up / thumbs down feedback collection to provide more in-depth visibility into user interactions with GenAI interfaces (e.g., correlating common topics, observing propensity to accept suggestions) and help with the prioritization of backlogs. Notable companies here include Pendo (a Sapphire Ventures portfolio company), Statsig, Context, Eppo, Nebuly and Tidepool/Aquarium.
Validation & Security
AI is the emerging category that is the biggest source of concern to IT and security professionals. As more GenAI capabilities move into production, there is a heightened awareness of the potential new vulnerabilities they can introduce to for organizations (e.g., prompt injections, malware in open-source models, etc.).
GenAI-Powered Interfaces Are Still Extremely New
Foundation model-powered interfaces represent a still unproven and untested method for accessing applications and their associated data sets. As a result, they bring with them cybersecurity, IP and reputational risks that can manifest in the form of unauthorized access; data leakage; dissemination of biased, harmful or misinformation; resource exhaustion; model poisoning; reverse engineering and more.
While real-world attacks on LLM applications have occurred, like the $1 truck purchase, the GenAI community has yet to experience a far-reaching breach (e.g., its version of a Solarwinds SUNBURST). We believe this is simply a reflection of the predominantly low criticality of the use cases GenAI supports today. As enterprises pivot to more mission– critical workloads, attacker focus—and more significant breaches—will inevitably follow suit.
Model interfaces must handle non-deterministic user inputs and model outputs, creating the need to augment traditional rules-based detection methods and access controls with additional layers of defense. We have seen a new wave of security solutions emerge in response, providing capabilities such as input sanitization, monitoring for hallucinations, data leak prevention and content moderation.
Frameworks and Best Practices Are Still Developing
In response to these threats, leading cybersecurity groups have begun to publish knowledge bases of adversarial attack vectors to better inform engineers and establish preventative best practices in the open. These include MITRE’s ATLAS framework, Google’s Secure AI Framework (SAIF), OWASP’s AI Exchange (and associated top 10 lists), CSA’s AI Governance & Compliance, as well as recent guidance set forth by the U.S. Department of Homeland Security. Emerging capabilities such as model scanners are playing an increasingly important role, and new AI governance platforms are providing control checks and policy enforcement across the model development pipeline to ensure adherence with still evolving regulatory frameworks.
Sub-Category Definitions
- Model Security solutions guarantee GenAI models are robust, reliable and resistant to unauthorized access, tampering and malicious attacks. These solutions encompass techniques and practices that safeguard models against vulnerabilities, such as adversarial attacks and model inversion. Notable companies here include Robust Intelligence, HiddenLayer, Protect AI, Guardrails AI and DeepKeep.
- Governance & Compliance solutions are tools and frameworks designed to ensure that GenAI systems operate within ethical, legal and regulatory boundaries. They help in overseeing the development, deployment and operation of GenAI models, ensuring adherence to data privacy laws, ethical guidelines and industry standards. At the same time, they facilitate transparency, accountability and risk management in GenAI applications. Notable companies here include Credo.ai, ValidMind, Monitaur, Holistic AI and Cranium.
- LLM App Security & Moderation solutions protect LLM-driven applications from threats, vulnerabilities and unauthorized access while maintaining the availability and integrity of the applications themselves using tools such as LLM firewalls. Notable companies here include Privacera (a Sapphire Ventures portfolio company), Lasso Security, Enkrypt AI, Calypso AI and Lakera.
- End-User Security solutions govern the usage of GenAI models and apps, monitor sessions and perform data loss prevention to keep private and personal data secure (and from being woven into 3rd party training data sets). Notable companies include Credal, Harmonic, Nightfall, Netskope (a Sapphire Ventures portfolio company) and Privacera (a Sapphire Ventures portfolio company)
Monitoring & Observability
The traditional MLOps market has produced a wide breadth of monitoring solutions intended to validate the integrity and reliability of models and their associated training datasets. These tools monitor both traditional system metrics (e.g. GPU/CPU utilization, response time), as well as ML model specific concerns such as accuracy (e.g., recurring checks against a defined eval metric such as PPV), drift (e.g., statistical variations between models at training time vs. production) and data quality (e.g., cardinality shifts, mismatched types).
Many of these same observability platforms, along with a new wave of GenAI–native providers, are now shifting focus to the LLM application layer. LLM observability tools build on traditional ML monitoring to capture important signals related to building, tuning and operating LLMs in the wild. For example, companies such as Weights & Biases (a Sapphire Ventures portfolio company) provide LLM tracing, allowing teams to visualize spans encapsulating prompt inputs, intermediary predictions, token usage, latency and more as transactions execute along a multi-staged LLM chain. The company is also focused on improving in-context learning methods, providing pattern identification and drift detection of unstructured data entities, such as vectorized embeddings, to improve the accuracy of RAG-based workflows.
For those interested in diving deeper into Monitoring & Observability, check out our blog post, “Observability in 2024: Understanding the State of Play and Future Trends.”
Notable companies here include Aporia, Arize, Arthur, Weights & Biases (a Sapphire Ventures portfolio company), Braintrust and Gantry.
End-to-End Training & Fine-Tuning Platforms
Providers in this space offer a converged platform for managing all the phases of the LLM model and application lifecycle. This approach simplifies the process of standing up a training and fine-tuning pipeline, reducing the tool hopping and effort required to stitch together disparate solutions. Common capabilities include a streamlined (often no/low code) interface for training and fine-tuning transformer-based models; access to model gardens, prompt engineering and experimentation playgrounds; support and integrations with common orchestration frameworks; monitoring; evaluation; safety and bias mitigation; application hosting and more.
While the traditional ML platforms and AutoML solutions have historically catered towards non-technical users, leading innovators such as DataRobot (a Sapphire Ventures portfolio company) have expanded to provide support for AI engineers and data scientists, with first-class support for Jupyter development environments.
“Over the last year, the AI market has experienced explosive growth and sprawl, and there is a need now more than ever for solutions that act as connective tissue across AI environments, assets and teams to ensure performance and minimize risk. With end-to-end AI platforms, businesses have the tools they need to operate AI with confidence, govern with full visibility and innovate rapidly to deliver results.”
Debanjan Saha CEO at DataRobot
Notable companies here include DataRobot (a Sapphire Ventures portfolio company), Deepset, Lamini, Wallaroo.AI and Qwak.
Conclusion
In the year since we put together our first internal draft of this GenAI App Infra Stack, we have revisited it countless times to reflect the rapid shifts in category definitions, capabilities, usage patterns and the absolute explosion in start-ups trying to address emerging needs.
We believe the categories and dynamics we have touched on are critical for companies as they work towards putting use cases into production and as the industry shifts from hype to real value creation. While some of the categories we have outlined will undoubtedly prove to be more temporal vs. durable and competitive dynamics will continue to shift, previous cycles in technology development suggest we are very likely to see huge outcomes driven by companies building the tools and key enablers of cutting-edge applications. We firmly expect to see a similar dynamic play out over the next few years as the next generation of companies of consequence emerges.
At Sapphire Ventures, we remain committed to backing and learning from AI-powered enterprise startups. If you are building in the space, we would love to connect at [email protected], casber@sapphireventures or [email protected].
Special thanks to the following individuals and companies for their input and feedback here, including Alex Lehman, Adam Liu, Jake DellaPasqua, DataRobot, Inbal Budowski-Tal (Pendo), Julian Wiffen (Matillion), Phil Gates-Idem (JupiterOne), Guhan Venguswamy (Jasper.ai), Liam DeCoste (PressW), Nikita Solilov (Responsiv.ai), Greg Hamel and Joshua Barclay.