How Did We Get Here?
Act #1: A lot of Pre-Work and Rigidity
Rewinding to the 1970s, Dr. Winston Royce, often deemed the “father of the waterfall,” came out with his iconic piece, Managing The Development of Large Software Systems, in which he described software development as a distinct sequence of steps. While Royce didn’t coin the term “waterfall,” he was instrumental in pioneering one of the earliest models of the SDLC. In many ways, the process was viewed similarly to manufacturing, whereby each step needed to be finished in its entirety before moving to the next.
Unsurprisingly, some obvious disadvantages, primarily inflexibility, emerged from this approach. All requirements, from a system and functional standpoint, needed to be well-known and fully hashed before any development could be greenlit. This was unsuitable for complex projects as it lacked the much needed agility to adapt to highly dynamic, unpredictable user requirements, and lead to prolonged processes, time wasted, imperfect applications, and, ultimately, unsatisfied customers.
Act #2: A Paradigm Shift With Agile
With the clear drawbacks of the “waterfall” method, the SDLC continued to evolve. In the early 2000s, a group of 17 engineers realized that the status quo was no longer viable, and introduced a new approach. They banded together, met up in Utah, and created the “Agile Manifesto,” which outlined four key values and twelve key principles to software delivery. Some of these principles were instrumental in redefining how work would be conducted and paved the way for the next phase of development.
The “Agile” approach focused on more frequent releases, catered to dynamic requirements and abandoned inflexible formalities. It encouraged closer collaboration between developers and business teams, and promoted delivery of software early and often. Since the Manifesto’s release, and the subsequent founding of the Agile Alliance (non-profit), the “Agile” method achieved ubiquitous adoption among software development teams through 2010 and onwards. The continuous iteration of “Agile” brought customers and development teams together, resulting in newfound agility and speed in software development.
Act #3: The Emergence of DevOps
Several paradigm-shifting developments created significant waves throughout broader tech markets, and subsequently, the SDLC. With the explosion in software consumption across all different industries and revolutionary technologies coming to the scene (software-defined infrastructure, modern cloud platforms, etc.), SaaS became the de-facto standard for delivering applications. This fundamentally altered the contract between software consumers and producers, as customers started demanding feature-rich applications with continuous improvements, and dynamic scalability. Releasing new features quickly and pushing the boundaries of software delivery started to make financial sense, triggering a never ending race to “out-innovate” and “out-perform.”
But delivering top-notch products to customers isn’t so simple as concerns arose around disjointed teams and overall dysfunction. Software creation actually involves highly coordinated execution across historically siloed entities: development, QA, ops, security, etc. While all these teams are ultimately working towards the same goal, the siloes lack visibility, leading to an abundance of issues from last-mile delivery delays to technical debt to fragile systems. And while the “agile” process promoted frequent integrations within the development team, practitioners have now turned to DevOps to unify all the relevant parties.
To us, DevOps is a cultural shift, a set of practices and an enabling ecosystem of tooling – anything that connects cross-disciplinary teams and encourages increased collaboration with the goal of delivering high-quality and sustainable products quickly.
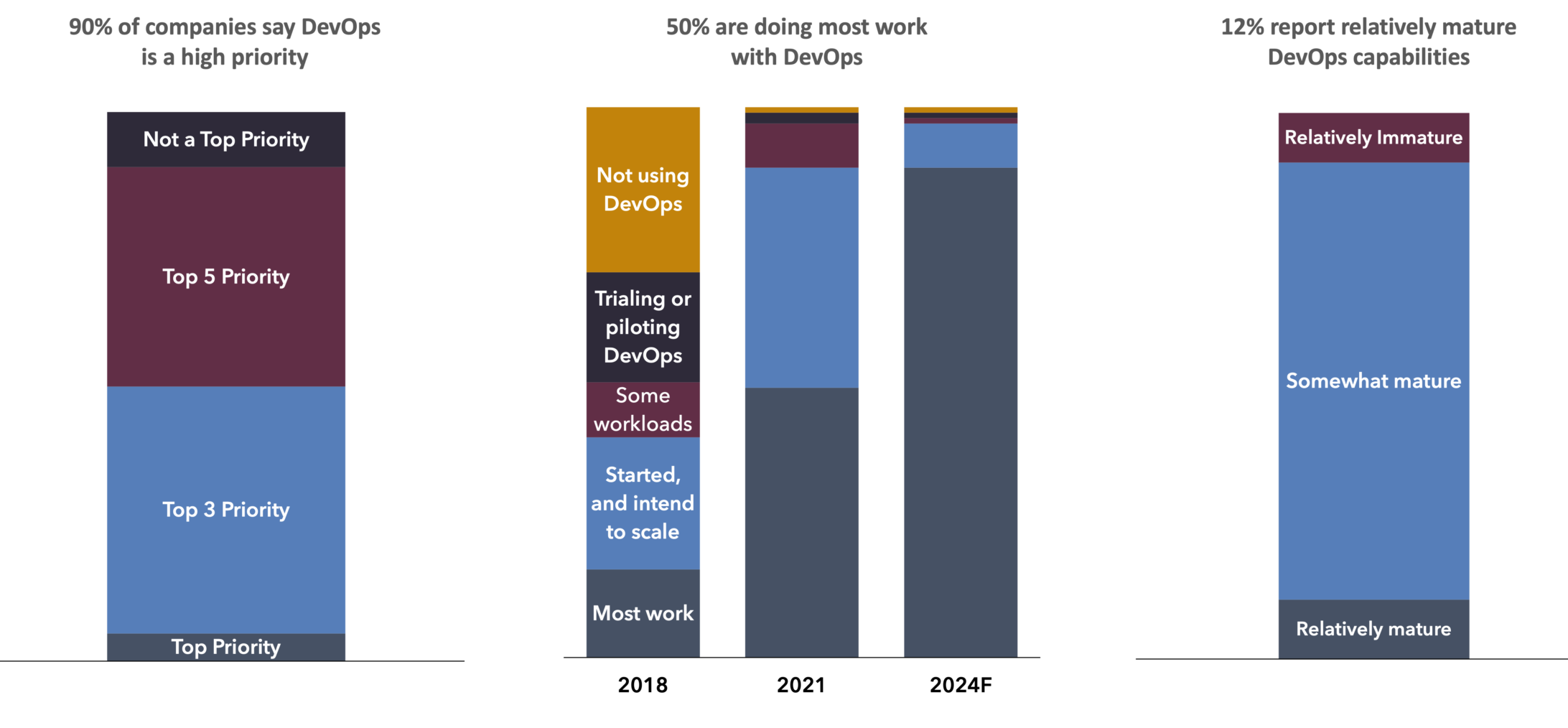
The data above shows that only 50% of companies have implemented DevOps at scale and only 12% of companies consider their associated capabilities mature. This disconnect suggests that we are still relatively early in the evolution of DevOps, and can be traced back to a few specific challenges:
1. Skills Uplift & Cultural Transformation. It is important to reiterate that DevOps is not just about the adoption of innovative tools and platforms. There is a significant human element involved in scaling DevOps practices, some of which is beyond pure technical expertise. Engineers that may have traditionally focused on a specific aspect of software delivery must now cultivate cross-disciplinary skills–like unpacking cybersecurity practices as part of the shift to DevSecOps–and learn how to better communicate and work across teams and functions. Additionally, as independent and siloed teams evolve into cohesive units, non-trivial amounts of time and energy is often required, potentially leading to widespread cultural friction and resistance.
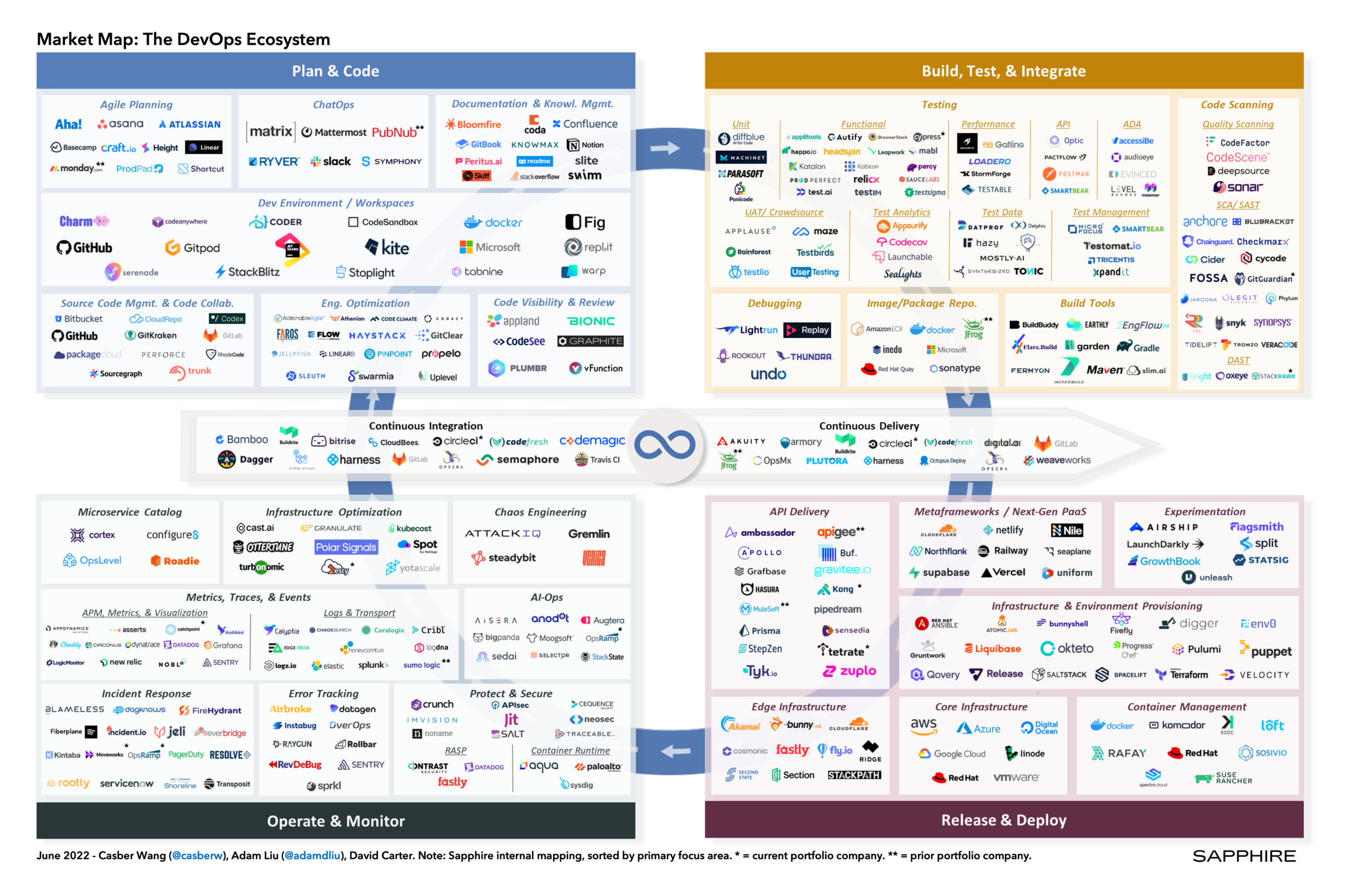
2. A Cambrian Explosion of DevOps Tools. Incremental improvements, emerging practices and niche use cases have spawned a vast ecosystem of literally hundreds of DevOps tools. In response, platform players have begun to acquire and expand horizontally, attempting to provide highly integrated solutions which address the end-to-end development lifecycle. However, highly specialized, best-of-breed alternatives still exist. This proliferation of DevOps tools and vendors, while driving innovation and value, has also increased complexity for modern dev teams. The abundance of choice can be overwhelming to practitioners, requiring them to work through nuanced differentiators and stitch together disparate offerings. And while it is easy to gravitate towards “next-gen” tools with promises of increased efficiency, implementations often bring significant engineering overhead and training cycles.
3. Legacy Environments. While IT shops are increasingly standardizing on some combination of cloud, containers, functions and microservices, many are still in a state of transition, supporting a hybrid of both legacy and modern tech stacks. Legacy or “brownfield” apps can be particularly challenging to ‘DevOps-ify’ because they are often built upon monolithic architectures, leverage static physical infrastructure that can be difficult to automate, and utilize more traditional frameworks and languages that lack continued investment and contributions from the broader DevOps community.
As we look ahead, we have identified a number of emerging DevOps trends, as well as noteworthy technology players within the different categories of DevOps, that we believe are helping to write the next chapter of this story.
1. Increased ML in the SDLC
Expectations for delivering exceptional product experiences have never been greater. As the arms race for new features intensifies, and the pace of modern software delivery increases, organizations have placed focused emphasis on optimizing all phases of the SDLC. However, companies can only scale engineering headcount so fast, and the proliferation of new tools can, at times, contribute to complexity vs reduce it. There is an obvious need for more autonomous, intelligent mechanisms for further optimizing software delivery. In response, ML models, capable of generating source code, optimizing test runs, remediating vulnerabilities, rolling back code changes, etc., have begun to revolutionize all aspects of the SDLC.
Design
Before code is written, engineers must thoughtfully evaluate architectural models and other technical design requirements based on the unique characteristics of a given workload. And as the product model is proven and market fit is established, teams will then often look to refactor their architecture in order to address growing customer demand and scale more effectively. But refactoring is a complex process, and in the case of so called ‘brownfield’ applications, is often avoided due to perceived risks and resource constraints. Emerging companies aim to automate this process, using ML to scan source code, discover interdependencies, recommend natural breakpoints, and automate necessary code changes to transition monoliths into microservices.
Code & Build
Many DevOps tools share a common goal of automating tasks that distract from the process of writing code and delivering features. However, even as developers put “hands to keys,” there are opportunities to augment their work with ML driven capabilities. In fact, the R&D team at Meta research believes that over time, programming will become “a semiautomated task in which humans express higher-level ideas and detailed implementation is done by the computers themselves.”
Within the IDE, ML driven products are providing predictive single line and full code snippet recommendations, alleviating the need to rewrite repetitive scaffolding and driving cross-team reuse of undifferentiated functions. Separately, as code is built, dependencies are pulled down from a variety of sources. These dependencies must be continuously updated as bugs and vulnerabilities are discovered and/or remediated within each, however the process for upgrading is not always so straightforward. New tools are using semantic code analysis to identify and transform specific lines and syntax that must be altered to prevent breaks as new dependency versions are introduced. Companies like Tabnine, GitHub (CoPilot) and Moderne are some of the illustrative vendors in the space.
Scan, Test & Review
As standard practice across the SDLC, engineers write a multitude of tests to validate different vectors including functionality, stability, performance and integrations into various systems. While critical, comprehensive test suites require significant engineering effort to write and can be cumbersome to maintain. Test suites also tend to balloon as new features are added (particularly within tightly coupled architectures), which can slow down lead times and reduce velocity.
Static scans are an important aspect of quality as they automate detection of deviations from coding best practices and surface potential vulnerabilities. Historically, solutions in this space identified highly repeatable stylistic patterns and well-known vulnerability signatures, generating tons of noise. Next-gen scanning tools are now training on large data sets (e.g. publicly available git repos) and using semantic code analysis techniques to interpret code, identify more nuanced bugs, recommend fixes and auto-remediate. Even human-in-the-loop review processes stand to benefit as companies are using ML to intelligently select appropriate code reviewers based on the scope of a merge, bandwidth of reviewers, and general familiarity of the project in scope. Companies like Jaroona (Veracode), Deepcode (Snyk) and Unreview (Gitlab) are illustrative examples here.
ML enabled tools have also come to market to automate the unit test generation process, streamlining workflows and freeing developers to focus on feature delivery. Similarly, functional end-to-end tests are also being optimized with emerging test platforms using machine learning to observe real application traffic and auto-generate end-to-end test cases based on common user flows. To supply these tests with appropriate inputs, companies are able to generate synthetic data that mimics production through usage of neural nets and other ML techniques. ProdPerfect, Cypress (a Sapphire investment), Relicx.ai and Tonic.ai are companies leading this movement in the space.
Finally, tests often require significant compute resources to execute. For example, Shopify runs 170K tests as part of their core monolith. However, not all test cases need to run on every build – and some can be skipped altogether based on the scope of a given code change. Test analytics platforms can use ML to optimize the test run process, analyzing call graphs to inform test selection and prioritizing the order of test runs based on historical analysis of failures to reduce test execution cycles.
Monitor & Maintain
Post deployment, SREs and on-call teams must continuously monitor and observe overall health, drawing upon huge volumes of data in the form of metrics, events and traces. As applications scale, both in terms of number of services and active users, the telemetry data they generate quickly reaches a scale that’s virtually impossible for any human engineer to meaningfully interpret. Modern observability and operations platforms are using ML to detect anomalies, correlate events and automate appropriate actions in response to predicted incidents. Bug tracking tools are also using ML to intelligently analyze and spot patterns in exceptions and errors to optimize triage and enable faster fixes. Other innovative companies are using ML to autonomously manage infrastructure, optimizing for spend and resiliency. Illustrative companies in this space include Zesty (another Sapphire portfolio company), Sentry, and Asserts.
2. Software Supply Chain Security
It’s no secret that supply chain attacks are on the rise. In fact, Sonatype’s 2021 State of The Software Supply Chain cites 650% YoY growth in associated attacks, and recent examples such as Travis CI secrets, OMIGOD agent and Log4Shell are painful reminders of their efficacy and widespread impact. The value to an attacker is clear: penetrate a single software provider’s defenses, and you can cascade an infection to all downstream users of that product, exploiting the trusted relationship between supplier and consumer. In response, a new ecosystem of emerging startups have spawned, aiming to secure various vectors of the software supply chain.
CI/CD Posture Management
One common supply chain attack vector is the CI/CD infrastructure itself where hackers can look to exploit unpatched build servers and overly permissive entitlements to gain access to source code repositories. New tools are entering this market aiming to validate the posture of well-known CI/CD platforms through enforcement of least privilege, multi-layered access controls and detection of anomalous activities and potential insider threat (e.g. a user suddenly cloning large sections of a codebase). Vendors in this space arming companies with tools to stop such attacks include Argon (Aqua Security), Cycode, Cider Security and Legit Security.
SCA, Code Scanning & Signing
Inspecting and validating the provenance of source code is a critical aspect of supply chain security. In particular, inventorying the open source libraries and packages consumed by a given application serves as a useful tollgate before code is deployed, and even post-deploy, as previously unknown vulnerabilities are discovered. Next-generation SCA tools are providing continuous inventorying and scanning of vulnerable open source dependencies, insights into package quality, author reputation, known vulnerabilities and flagging restrictive licenses. Additionally, emerging secrets scanning tools are detecting sensitive materials (e.g. API keys, tokens, certificates, passwords, etc.) embedded in source code. Other emerging tools are scanning and dynamically optimizing container images, to remove bulky or dangerous packages in part to reduce the overall attack surface. And code signing frameworks are executing provenance checks needed to ensure packages are distributed from a trusted source. Illustrative companies in this space include GitGuardian (a recent Sapphire investment), R2C, Slim.ai and ChainGuard.
Dynamic Analysis & Vulnerability Response
While SCA and other static scanning tools are useful for discovering where a vulnerable package version exists, they often struggle to grasp the extent to which that CVE is actually exploitable. Next-gen DAST and other dynamic scanning tools are addressing these challenges, embedding directly into CI/CD workflows and helping teams triage those CVEs that pose a clear and present risk with scans that assess the application from an attacker’s perspective, outside-in. These tools can be an effective tollgate for detecting whether a fully built web application or API is at risk. Illustrative companies in this space include StackHawk (a Sapphire portfolio company) and Noname Security.
And, as notifications and alerts from these various layers of defense start to flood the inbox of DevSecOps and engineering leads, there is a need to streamline vulnerability response. XDR platforms are offering visibility into where a given vulnerable package is running. And new emerging cyber tools are providing additional context into the relevance and priority of a given alert while facilitating communication between teams, recommending fixes, and automating downstream remediations.
3. Continuous Experimentation and Shifting Right
The principle of “shift left” suggests that certain steps of the traditionally sequential software development lifecycle should be performed as early as possible, and throughout the cycle, to avoid costly redesign and rework downstream. The concept initially focused on quality testing practices, but has since expanded to other disciplines such as security scans.
While shifting these practices left is important, there are facets to effective product delivery, which are in many ways dependent on production environments. For starters, staging environments and associated test data are rarely indicative of the real world, even with significant time and resources invested into trying to mirror the two. Additionally, the efficacy and impact of new features can only truly be observed through measured adoption rates and feedback from real users. Historically, engineers have avoided testing in production over concerns of revenue loss and reputational risk tied to the potential release of buggy code. However, a combination of disciplined DevOps practices and emerging tools have begun to redefine these norms and “shift right” many aspects of the delivery lifecycle.
Feature Flags
Feature flags (or feature toggles) manifest as conditional statements in a code base which then modify the behavior of an app based on specific parameters (e.g. request headers). Toggles have emerged as a powerful means of introducing code changes into production, backed by fine grained control and decision logic governing which user segments are presented with a given feature. They allow teams to effectively test different versions of an app in production while controlling the blast radius. Modern feature flag platforms also come with robust analytics engines, providing insight into adoption, usage and performance of individual features. They are seen as enablers of trunk-based development practices, offering a safer way to ship code by hiding incomplete or untested features behind flags. We are excited about emerging open standards in this space like OpenFeature, as well as companies such as Statsig, Split Software, Unleash, and LaunchDarkly.
Continuous Verification
As teams shift right and depend more and more on validating software after it has been deployed, they are faced with an increasing need to rapidly detect regressions and rollback in the event of an issue. Continuous verification (or validation) platforms are coupling the automation and multi-cloud deployment capabilities of CD platforms with the robust telemetry of modern observability platforms. Whereas teams may have performed manual health checks following deployment in the past, continuous verification platforms like Vamp (CircleCI, a Sapphire portfolio company) and Harness can ingest observability data from a multitude of sources and then use ML to assess performance, establish baselines, detect deviations and automate rollback in the event of a potential incident.
4. Focus on Measuring and Improving Engineering Productivity
Engineering talent is a perpetually constrained resource. The WSJ recently reported that employers posted over 340K unfilled IT job openings (spanning a variety of role types, geographies and industries) just this past January, 11% higher than the 12-month average from the prior year. To further exacerbate this challenge, the number of new tech roles being created far outpaces the number of new engineers qualified to fill these roles. The stark discrepancy between unfilled positions and the availability of top talent, coupled with broader macro trends such as the shift to distributed teams and flexible work policies, have spawned a new breed of innovative tools aiming to more effectively measure engineering productivity, optimize resource allocation, pinpoint burnout and onboard new hires faster.
Code Visibility
Codebases are often highly complex, consisting of thousands of lines of code, containing numerous interdependencies, and contributed by a multitude of engineers. Whether a new developer is trying to unpack one module within a broader codebase or a tenured manager is reviewing an oversized pull request, it’s universally a difficult task to understand how the different pieces truly tie together. Code visibility tools like CodeSee, AppLand and Plumbr can help both new team members quickly orient around a codebase and existing team members gather important context during code reviews, and tangibly visualize how changes might impact the broader application.
Measuring Engineering Productivity
Engineering teams are highly dynamic as agility and flexibility have become paramount to modern software delivery. With so many disjointed processes in places, it becomes difficult to understand the development organization’s state, and identify core strengths and weaknesses. Engineering productivity tools shine here as they bridge this gap, giving engineering leaders and developers a tangible way to extract actionable insights on development productivity and identify early signs of burnout.
In tandem, advanced analytics help teams proactively identify bottlenecks thereby increasing key KPIs such as cycle time, deployment frequency, change lead time and so on. Companies like Propelo, Jellyfish, LinearB and many others in the ecosystem do this by integrating with common DevOps tools, ingesting mountains of data and then painting a holistic snapshot of the value stream. In turn, measurement of common DevOps metrics (e.g. DORA) coupled with more real-time visibility, help improve engineering efficiency and move teams closer to operational excellence.
5. Next-gen Development Environments
It is important to continue to find new ways of elevating the developer experience. Whether via a consistently powerful dev environment, temporary environments for testing, staging, etc., spinning up remote deployments can equip engineers with newfound improvements in speed, power, security, etc. Teams are no longer solely confined by their local machines and are able tap into innovative solutions that can extend functionality beyond the status quo.
Cloud-based IDEs / Headless Dev Environments
The current status quo for coding is, and has been, via an IDE on a local machine. Such development practices have been labeled as fast, easy and convenient. However, cloud-based dev environments attempt to iterate on the status quo and elevate the overall experience. Illustrative vendors in this space such as Coder, StackBlitz and Gitpod provide teams with more powerful, flexible, secure and consistently reproducible workspaces. Rather than relying on local CPUs/GPUs, compute power can be scaled in the cloud rapidly as needed. And as source code is decoupled from local machines, endpoints become more secure and overall posture can be advanced. Configuration drift and ramp-up time can also be significantly minimized as developers all receive a more repeatable, consistent build.
Environments-as-a-Service (EaaS)
Environments are collections of both hardware and software tools that engineers use for development. Typically, environments support four main stages: development, testing, staging and production. Each step serves different, yet critical, purposes. For example, the IDE is crucial for writing code, whereas test environments are pivotal for identifying bugs and ensuring quality. While local, inner loop environments can be relatively straightforward to set-up, testing and staging are often more complex. These intermediary environments are designed to resemble production and require significant infrastructure configuration and setup time to implement consistently and efficiently. EaaS vendors like Release Hub, Okteto, Bunnyshell and AtomicJar have become increasingly popular as companies strive to abstract infrastructure management. With one-click, companies can spin up ephemeral environments that are shareable, repeatable and versioned, enabling teams to validate changes and release to production quicker, and with more consistency.
Closing Thoughts
DevOps, both as a cultural mindset, and as a set of tools and practices, is still early in its evolution. Implementing and scaling this discipline effectively can be the difference between market laggards and category leaders and, as a result, innovators will continue to iterate and push the boundaries of what is achievable in software delivery.
As application architectures and tech stacks continue to evolve, we have and will continue to see an explosion of new tools and capabilities in this space. While this post only highlights five trends, we are incredibly excited as we look forward to other trends–WebAssembly, Meta frameworks, Web3 dev tools, etc.–and the potential for numerous companies of consequence to be produced in the years to come.
If you are a DevOps company and/or contributing to the evolution of the SDLC in any way, please reach out to [email protected], [email protected] or [email protected]. We look forward to hearing from you!
Special thanks and shoutout to Alexey Baikov, Ramiro Berrelleza, Steve Chin, Shlomi Ben Haim, Jai Das, Milin Desai, Scott Gerlach, Shomik Ghosh, Dan Nguyen-Huu, Anders Ranum, Baruch Sadogursky, Roopak Venkatakrishnan for reading drafts and contributing their thoughts.