When people think of AI and machine learning, self-driving cars, robots or supercomputers often spring to mind. But in reality, the AI use cases that are driving business results aren’t that sexy–at least not in the conventional sense.
For a while now, we at Sapphire have been very excited about what Databricks CEO, Ali Ghodsi, has dubbed “Boring AI”–using AI to drive tangible business value through reduced costs, increased revenue, improved human productivity and more.
Through the power of AI, marketers are gleaning greater customer insights and recommendations, manufacturers are predicting supply chain bottlenecks and insurance companies are more accurately assessing risks. It’s why the market for enterprise AI is growing at 35% annually and is expected to reach nearly $53B by 2026. It’s no wonder that positions for AI specialists and data scientists (a precursor to AI) are up 74% and 37%, respectively.
We’re seeing first-hand how AI is gaining adoption across several enterprise use cases, right within our portfolio. A few example applications include:
- Sales: Analyzing how customers interact with content so sales teams can adjust their techniques and drive more efficient customer acquisition.
- Security: Leveraging machine learning to detect fraudulent and abnormal financial behavior for customers.
- Product: Using AI-based technology to transform both live and recorded video and audio into highly-accurate captions and transcripts.
We believe much of the rapid uptake in AI adoption over recent years can be attributed not only to new software platforms helping to operationalize AI, but also (and maybe even more directly) to advancements in core computational hardware enabling information processing across massive volumes of data. With the rise of GPU computing (general-purpose parallel processing) as well as AI-focused ASICs (application-specific processing), like TPUs (Tensor Processing Units), practitioners today are able to analyze large amounts of data in a cost-effective and scalable manner allowing for AI workloads to run broadly across the business and answer high-impact operational questions.
As AI and machine learning continue to attract more attention and create new and exciting possibilities, businesses expect to build & deploy AI applications in a more streamlined fashion. Where organizations used to seek all-in-one solutions to operationalize machine learning (ML) due to limited in-house resources and expertise, we’re seeing a rise in the demand for modular, best-in-class tooling that equips today’s more robust ML teams with the ability to flexibly run highly-custom and performant ML workloads. ML teams are also increasingly looking towards third-party software vendors (instead of building their own custom tools) to manage the individual components of their modeling workflow due to the system-level technical debt that in-house ML tooling accumulates (great article from Google on this phenomenon within the ML field specifically, published in 2015). This has been a significant driver of demand for the next-generation of ML tooling companies – a category of technology platforms we are incredibly excited to highlight in this article!
But first, it is important to understand why the AI market is trending more modular – and for this, we must explore who’s driving this change. Let’s take a look at how the market is currently dividing AI users.
3 core AI user types: “Off-the-Shelfers”, “Bet-the-Farmers”, “Rocket Scientists
1. Off-the-shelfers: These AI users are everyday business analysts who bridge the gap between IT and business outcomes to deliver data-driven insights and recommendations. Already proficient in Excel (and, in many cases, structured database languages like VBA and SQL), they can quickly become AI specialists with minimal upskilling given accessible AI tooling.
True to their name, these customers want “off-the-shelf” products that solve their immediate business problems. They don’t necessarily want to know how the algorithm works, they just want to know that it works. Abstraction of the various components of the AI model building and deployment workflow is critical to demonstrate tangible value to this user group. With all-in-one AI tools, “off-the-shelfers” can apply AI and machine learning to basic tasks in just a few clicks and see near-immediate results. Off-the-shelf tools are especially attractive to fields like marketing, finance and healthcare where forecasting, analyzing time series and finding causal effect dependencies between variables offer greater decision-making capabilities.
2. Bet-the-farmers: Bet-the-farmers are (often) part of larger organizations willing to spend millions of dollars and hire teams of data scientists to build custom machine learning operations that unlock major insights from big data.
Bet-the-farmers build targeted solutions aimed at ‘million-dollar questions,’ like how to find a 1% improvement on car insurance premiums, predict medical insurance costs or anticipate supply chain delays. It’s about shaving basis points off of inefficient or ineffective processes given the large, dollar scale of their operations, which often equates to millions in reduced costs and boosted profits.
For bet-the-farmers, how they build their machine learning capability is just as important as what they build. Because there’s so much complexity within these organizations–including skill set diversity, lack of effective talent onboarding (both in terms of enabling ML experts to easily plug in their expertise and driving upskilling across newer talent), proprietary on-premise data centers, simultaneous cloud initiatives, and so on–these organizations often need custom-built machine learning solutions.
The way we see it today, bet-the-farmers have the biggest opportunity for investment in AI initiatives. Machine learning adoption within the segment is still low relative to budgets, but with such vast potential, it’s only a matter of time before bet-the-farmers adopt machine learning en masse.
3. Rocket scientists: These users are the ultimate AI brainiacs: hyperscaling tech companies, literal rocket scientists, pharmaceutical and biotech analysts, who are highly code-literate and technical enough to build their own AI solutions. These companies are staffed with highly-skilled AI practitioners who have the necessary know-how to stand up a complete, end-to-end tool stack in-house for hyper-specific AI workloads. Employers, particularly across the FAANGs, typically pay these individuals top-dollar given the high demand for their skill sets.
Rocket scientists don’t necessarily need a commercial platform. Instead, they custom-build their solutions or use open-source code, as they know the exact tools they need and how to troubleshoot problems.
Though this market is more mature from an AI technology adoption standpoint, it’s worth asking, “what could we take from their world and apply to the bet-the-farmers?”
All three customer categories have different machine learning needs and expectations. But, as more and more large organizations invest big money into AI initiatives, we see bet-the-farmers as the market-defining customer segment that will drive the bulk of AI enablement technology adoption in the coming years.
Why integrated solutions are winning today
Automated machine learning (AutoML) solutions simplify the end-to-end AI lifecycle by handling core workflow components including data preparation, model selection and training and deployment–all through a single, integrated platform. Through drag-and-drop functionality and easy-to-understand visualizations, these platforms arm citizen data scientists (i.e., data and business analysts) who, just a couple of years ago, outnumbered technical data scientists by over 100x1, with powerful AI platforms.
Thanks to AutoML vendors like DataRobot (Sapphire portfolio company), enterprises that lack armies of skilled data scientists can deploy production-grade machine learning workloads. AutoML platforms have helped answer high-impact questions for businesses regardless of industry. For instance, DataRobot teamed up with the Philadelphia 76ers’ ticket sales team to identify fans most at risk of churning and prioritize their customer engagement initiatives to drive retention.
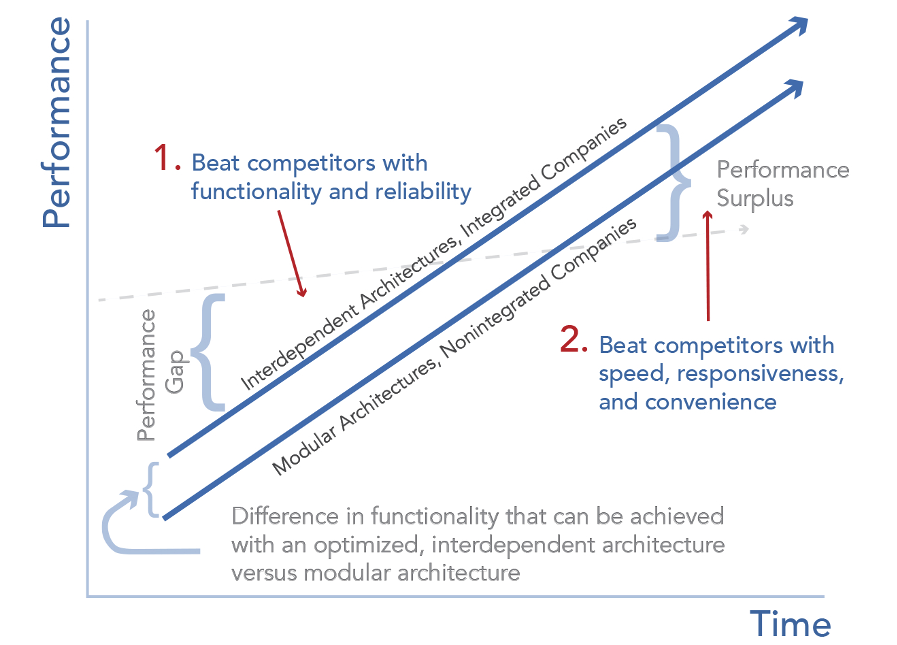
These all-in-one integrated solutions offer a practical avenue for organizations to take advantage of the advanced analytics that AI/ML promises. And they’ve gained enduring popularity today for one primary reason: Success in the early days of a market is by and large determined by product performance and functionality.
Moving from an interdependent platform to a modular architecture
As AI use-cases become more sophisticated and more people are trained in advanced data science, enterprises won’t just want integrated black-box systems anymore. They’ll want the flexibility to tweak every last component of their model and model-building workflow to produce the most optimal analyses and systems for their specific needs.
Today, customizing different components of the ML lifecycle is highly manual, with practitioners largely taking a DIY approach. Though this may be palatable for the “rocket scientists,” most businesses prefer some degree of abstraction from the underlying functions and hardware in each step of the modeling process as they don’t have (nor want to invest in) the in-house resources to custom-build core capabilities like data labeling, experiment tracking, model monitoring, etc. Rather, we see the majority of organizations opting for best-of-breed solutions from focused vendors to gain additional control over their modeling workflow without needing to be too concerned with what’s going on “under-the-hood”.
Expand 
Source: Clayton Christensen’s Modularity Theory
Soon, large data teams will turn to modular toolkits with dozens of solutions that manage different stages of the AI lifecycle. This will be particularly true of the “bet-the-farmers”, who will need customized, best-in-class tools that provide the flexibility that can match their exact challenge.
At this point, performance will no longer be the market’s sole requirement. Instead, vendors will favor differentiation through customization to stay relevant. This leads to modularization of the entire AI stack, where users can set up an AI modeling function internally to fit within their specific organizational constraints and objectives.
But, to narrowly say modular solutions are the future or interdependent architecture is doomed when the market matures would also be false. In fact, for “off-the-shelfers” and “bet-the-farmers,” usage of both types of AI platforms is growing. Instead of a full takeover by either approach, the market is heading towards a “meeting in the middle” between modular and interdependent architectures.
We’re seeing platform players evolve to become more modular–making moves like DataRobot’s recent acquisitions of Zepl (collaboration) and Algorithmia (deployment), for instance–in the hopes of providing more technical users with advanced development environments where data scientists can bring in their own custom code.
At the same time, many modular players are realizing that offering one small part of the toolchain isn’t enough. They need to start pitching business value too, so several vendors are also moving towards offering more extensive functionality.
Last but certainly not least, modularity is an expensive design choice. A truly modular tech stack is a significant investment, requiring strong communication between the individual platforms that it is composed of. Today, ML teams spend resources building connections between different tools using custom scripts–and in some cases, these teams give up and build custom solutions instead. So while we do see more modularity coming in a meaningful way, we expect longer-term that the degree of fragmentation will remain at a reasonable level and platforms will continue to thrive.
How we see AI’s modular universe developing
At Sapphire, we’re fortunate to have backed a number of companies solving critical challenges across the AI lifecycle, which keeps our finger on the pulse of rising trends. We were the first institutional investor in Alteryx (NASDAQ: AYX) and led two consecutive private market rounds in DataRobot. What we’re seeing today is that although AutoML solutions largely abstract the modularity from today’s solutions, behind the scenes the AI lifecycle is already incredibly fragmented.
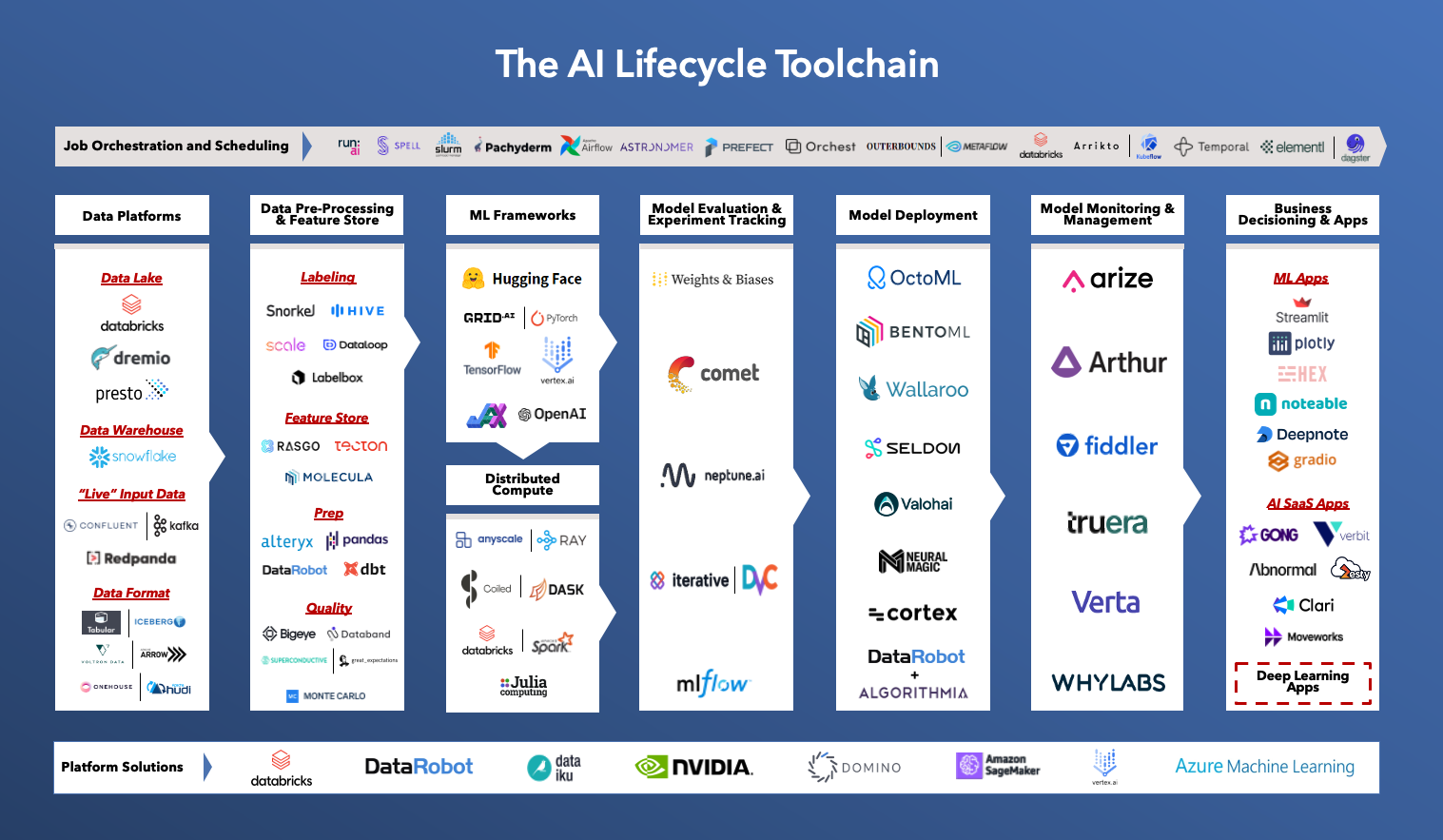
Here’s how we see the AI lifecycle toolchain developing as tech stack modularity becomes more pronounced:
Data Platforms
Getting the right data to the right downstream AI/ML systems is a major undertaking today. As businesses increasingly capture more volumes and varieties of data, platforms that can help aggregate data assets and support the data needs of the AI/ML pipeline become critical. Companies in this space include data warehouses and data lakes and lakehouses like Snowflake, Databricks and AWS S3 as well as Query Engines such as Sapphire portfolio company Dremio and Presto/Trino.
Data Pre-Processing (Labeling, Preparation and Quality) & Feature Store
Data processing is the process of transforming raw data into a usable format for training ML models, which includes sourcing data, ensuring dataset completeness, adding labels and transforming data to generate features. Most data comes in with missing or erroneous data points, which can alter the accuracy of ML models once they are launched into production. For more complex machine learning and deep learning models, users need a stream of labeled training data (based on raw data), which often comes in through either hand labeling, programmatic labeling or synthetic label generation.
In addition to transforming the data, many solutions in this category also evaluate the quality of the datasets to ensure they have the right diversity of data points for all scenarios and that the data has been properly pre-processed for successful model outcomes. Companies in this space include Scale, Labelbox and Snorkel.
ML Frameworks
Once data is cleansed and prepared for analysis, AI scientists must determine the optimal model type and hyperparameter configuration to drive the best outputs. Usually, a model is selected by running it against a training data set to determine model fit, a validation data set to evaluate model performance while tuning hyperparameters and a test data set to determine real-world accuracy. Platforms enabling efficient model selection and training include Hugging Face, PyTorch and TensorFlow.
Distributed Compute
Modern AI/ML training often involves gigantic data sets and powerful compute engines to run data processing on. Distributed data engines orchestrate the compute to run processing across clusters of servers. Open-source platforms like Dask, Ray and Spark have quickly gained popularity for enabling ML engineers to easily process big data workloads at scale and in less time. Because distributed platforms are hard to set up and maintain, commercial entities have emerged to build managed experiences to support large-scale data projects. Companies in this space include Coiled, AnyScale and Databricks.
Model Evaluation & Experiment Tracking
Much like the importance of tracking metadata and versioning within software development, it’s critical for AI/ML teams to track the logs, data and code associated with model training. Building models is an empirical science, requiring many iterations involving specific adjustments across countless components of the model- and infra-level code. End-users need a system-of-record of all changes made to enable seamless collaboration and greater fine-tuning of AI/ML initiatives across their business. As a last step in the model experimentation process, engineers prefer to push the final version into a model “registry” where other ML engineers or individuals across the business can easily access it. Companies in this space include Weights & Biases, Comet.ML and Neptune.ai.
Model Deployment
Once a model is selected and trained, it’s ready for deployment. Model deployment tools integrate with the underlying ML infrastructure and operations tools, as well as the production environments to optimize model performance and streamline the process of pushing models to production. Tools in this category abstract ML engineers away from infrastructure- and hardware-level decisions and coordinate the work of IT teams, business people, engineers and data scientists. Companies in this space include OctoML, Algorithmia (acq. by DataRobot) and Valohai.
Model Monitoring & Management
As important as it is to get the model to production, monitoring the performance of the model throughout its lifecycle, from research to production, proves to be an equally critical step. Model monitoring tools seek to identify problems as a model transitions from a contained research environment into the real-world. This includes tracking metrics around model uptime (availability), identifying model drift (loss of performance due to widespread changes in production data characteristics versus training data sets), flagging data quality degradation and more. A subset of this category is focused on driving AI explainability, which means helping engineers and business-users to understand the outputs of their AI/ML models. Companies in this space include Arize, Fiddler and WhyLabs.
Business Decisioning & Apps
What makes the potential for AI/ML so exciting is the plethora of upcoming business applications designed to leverage advanced analytics to answer important questions across the enterprise. Whether it’s purpose-built software addressing specific use-cases out-of-the-box (e.g.,Gong, Abnormal Security or Sapphire portfolio companies Clari, Moveworks, Verbit, Zesty etc.) or development frameworks enabling users to build flexible data apps (e.g., Streamlit which was recently announced to be acq. by Snowflake, Plotly), the companies building the application layer of the AI/ML stack are completing the last-mile promise of AI by delivering practical and actionable outputs to the business.
Deep Learning
Deep learning is a more complex subset of ML, which involves several layers within the neural network. It’s seeing adoption across the data science community as businesses seek to identify new opportunities for automation and understand additional, key insights across their operations. However, due to the historical lack of adequately-sized, labeled datasets and cost-effective computing power at scale, deep learning workloads have mostly been run in research environments.
As training methods evolve (e.g., unsupervised learning) and efficient hardware and processing systems emerge, we believe we’ll see more wide-scale adoption of deep learning both across AI digital natives and more traditional enterprises investing in their data science efforts. Looking across the numerous real-world examples of deep learning at work–whether it’s hyper-functional virtual assistants, a whole category of autonomous vehicles like Rivian and Tesla or even other “Boring AI” applications across core industries like healthcare (e.g., medical image analysis) and manufacturing (e.g., predictive machine maintenance)–the possibilities for improving business and society are limitless!
Job Orchestration and Scheduling
While job orchestration tools and schedulers have grown in popularity across AI/ML engineers because of their ability to streamline and automate components within the broader modeling workflow, they aren’t necessarily intended to run and manage the full AI lifecycle. ML models must continuously run, learn and update to remain highly performant–to ensure this happens in a structured and repeatable manner, orchestration tools help ML teams schedule different components of the ML pipeline (e.g., model training, evaluation, etc.), manage dependencies (e.g., manage dependent data flows) and more. With any modular tech stack, it is also critical that the different components talk to each other seamlessly. This is another area where job orchestrators can add value as a layer of abstraction that connects disparate tools and allows ML teams to operationalize their modular tech stack quickly. Representative companies in this space include Pachyderm, Prefect, Iterative/DVC and Arrikto/KubeFlow.
Platform Solutions
Platform solutions take cleaned and prepped data and test several different models to identify the best fit and highest accuracy algorithms for the task at hand. Though this process doesn’t always result in the optimal model being selected, it serves as a good baseline for teams that lack data science knowledge. It also saves data scientist resources and time, reducing the manual work that the process would otherwise take. Companies in this space include DataRobot, Dataiku and Domino.
The takeaway
The market for AI/ML technologies is growing rapidly as organizations, agnostic of industry, seek to leverage their evergrowing datasets to inform better decision-making across their businesses. As a result, these organizations are increasingly demonstrating a meaningful appetite for investing in the necessary resources–whether it be top-tier ML talent or software tooling–to enable the creation and maintenance of robust internal ML functions.
We’ve now seen an explosion in new technology vendors that are identifying highly-efficient methods by which to address the myriad of core tasks across the full AI/ML lifecycle. Now more than ever, it’s becoming clear that there’s ample opportunity for numerous companies of consequence to be built to serve AI/ML teams with best-in-class software solutions. We’re looking forward to seeing how the AI universe develops as it becomes more modular, and new tooling categories emerge.
If you are working to address this massive opportunity, please reach out to Casber at [email protected] and Adi at [email protected]. We look forward to hearing from you!
Thanks to Seann Gardiner, Luis Ceze, Dmitry Petrov, Manu Sharma, Steve Rodgers, Ben Rogojan, Jakub Czakon, Jared Parker, Kevin Guo, Alexander Gallego, Eran Shlomo, Gideon Mendels, Jason Lopatecki, Aparna Dhinakaran, Shomik Ghosh, Justin Gage, and Asif Moosani for your feedback. And shout out to our summer intern, Will Ziesing who was instrumental in putting this article together!
1 Per Gartner, IDC, BAML, JP Morgan and the US Census