Reinforcement Learning is Becoming a Strategic Priority for Frontier Labs and Enterprises – The Innovators Shaping the Market
LLMs got smart by reading the internet. They ingested trillions of tokens of text, learned patterns in language and became very good at predicting the next token. But prediction alone isn’t enough to build AI that can actually do things.
It’s like teaching someone how to golf. You can show them every rule of golf, hand them a detailed map of all 18 holes, break down the perfect swing frame by frame and have them watch every instructional video on YouTube. But until they’re grinding reps on the range and logging real rounds, they won’t actually improve.
The same is true for AI. To go from chatbot to capable agent, models need a fundamentally different kind of training called reinforcement learning (RL).
Inside the Training Loop: How Does Reinforcement Learning Work?
At a high level, RL systems have 4 key components:
- The Environment. The environment is a simulated version of the software or system in which the agent will operate. It could be a cloned version of Salesforce, a git repo, a browser, a spreadsheet, or a production system. The environment defines what actions the agent can take (clicking, typing, running code, searching) and the context those actions operate within.
- Environments can be as simple as a single-state form or as complex as a multi-step workflow with numerous possible actions, configuration states, and branching paths. In the context of our golf analogy, this is the golf course itself, the hole layouts, the hazards and the conditions the agent (golfer) will need to navigate through.
- The Task. Within that environment, the agent is given a specific objective to complete. It could be resolving a customer support ticket, completing a multi-step checkout flow, generating a formatted report from raw data or debugging an obscure technical problem.
- Similar to environments, tasks can also range from straightforward and single-step, to deeply complex, requiring the agent to think, plan, adapt, and recover across many sequential actions. To keep rolling with our golf analogy, how do we take the perfect sequence of shots and get the ball in the hole?
- The Verifier (or Grader). Once the agent completes its task, a verifier checks whether the outcome was correct. In some cases, this is straightforward. In other cases, it might be subjective. Did the unit tests pass? Does the answer match a known value?
- For open-ended workflows, verification becomes harder, often requiring a human grader or an LLM-as-a-judge to score against a rubric. The quality of the verifier matters enormously, as a poorly designed grader creates an opening for the model to game the system, or ‘reward hack,’ optimizing for a high score rather than actually solving the task at hand. The scorecard doesn’t lie. Did you make par or a triple bogey?
- The Feedback Loop. Once scored, the feedback is run through the model’s weights, ultimately reinforcing successful strategies and penalizing those that weren’t.
- Tasks are typically organized into a curriculum that gradually increases in difficulty, ensuring the agent builds foundational skills before tackling more complex workflows. Run thousands of times across thousands of different tasks, the loop compounds, and what initially was a model that could only read about how to act, becomes one that has learned through experience. You can golf now – let’s go!
This training feedback loop is why RL environments have become one of the most important inputs in agent development today. The quality of the environment directly determines the quality of the agent that comes out the other side. Better environments produce better training signals, which produce more capable models. This relationship is what’s turned RL environments into a strategic priority for frontier labs and enterprises.
The Missing Ingredient: Why Do We Need Reinforcement Learning?
Pre-training no doubt gives LLMs an incredible foundation. Models with no RL already have broad knowledge, strong language skills and basic reasoning abilities. In some cases, teams take their models one step further and layer in Supervised Fine Tuning (SFT), which exposes models to specific domains and proprietary knowledge (e.g., internal docs, product-specific workflows, behavioral data, niche coding languages, etc.) to incrementally drive efficacy.
However, pre-training, even if you do SFT after, doesn’t teach a model how to act. Knowing what good, grounded text looks like is very different from knowing how to navigate a multi-step workflow, recover from mistakes or make a judgment call in real situations.
This gap is becoming more critical as the industry moves from models that answer questions to agents that do real work such as booking travel, resolving support tickets, managing CRM pipelines, writing and testing production code, and so on. Pre-training doesn’t give models that kind of practice, but RL does. Over many iterations of tasks in RL, the agent learns not just what to say, but what to do.
This is how Anthropic’s Claude Code and Cursor’s Composer got so good at coding, how OpenAI’s reasoning models can work through complex multi-step problems, and the list goes on. As frontier labs, enterprises, and tech-forward companies alike race to deploy capable agents, RL is the engine underneath that differentiates the ones that actually work.
And as pre-training and SFT hits its ceiling, labs and enterprises alike are now betting on RL as the next frontier for improving agent capabilities, especially for longer and more complex tasks. That bet is driving a wave of investment into the environments and infrastructure needed to make it work.
Who’s Buying? Labs Lead, Enterprises Are Next
The buyer landscape for RL environments today is split into two camps across frontier labs and enterprises. Frontier labs have the strongest appetite today as labs like Anthropic, OpenAI, Google, Meta, xAI, etc. are investing heavily on RL environments to train their next generation of models.
In practice, given the nascency, the business model and engagement are still fairly fluid. Some labs have built out full internal teams for this, like dedicated data operations groups that act as a middleman between researchers and vendors, handling purchasing and QA. Others still take a more decentralized approach, where individual researchers source and manage vendor relationships directly. Either way, the process typically starts when a research team within a lab identifies a capability gap it wants to close. From there, the team describes what it needs, writing a task spec that outlines which domains it wants to cover, how hard the tasks should be, and what the verifier needs to check for. A vendor then builds the environment, typically with a team of engineers who have deep expertise in the target domain. The research team reviews the output, stress testing it for quality and ensuring the difficulty distribution matches what’s actually useful for training. Once accepted, the environments get plugged into the lab’s RL training infrastructure, where the RL loop can begin. The whole process today is iterative, but collaborative.
There are only a handful of frontier labs in the world, which means vendor revenue is concentrated among a smaller number of customers, but the urgency and appetite among these buyers is the highest. RL environments directly feed into model capability gains, and in an arms race where each new model release is a competitive event, the labs that train on better environments and more RL ship with increased efficacy. As such, spending in the RL environment space is growing extremely fast, with Anthropic reportedly planning to invest over $1 billion in the space over the coming year.
Enterprises will also be key buyers of RL. Key word here being “will” as they are mostly all very early in their journeys. The majority of organizations today don’t have in-house RL expertise, so they’re turning to companies that can come in, embed with their teams and build agents tailored to their specific workflows. DoorDash’s recent acquisition of Metis, a research lab focused on post-training for enterprise agents, shows how seriously large companies are taking this. As more enterprises move agents into production, we expect this side of the market to quickly grow and sophistication to increase quickly.
What Does it Cost? The Economics of RL Environments
Pricing in the market breaks down along two dimensions: the environments and the tasks. The cost of an environment depends on how complex it needs to be. A basic website clone might run tens of thousands of dollars, while an intricate enterprise tool with dozens of interconnected features can cost several hundred thousand dollars.
Tasks that frontier labs also help generate are cheaper on a per-unit basis, typically ranging from several hundred to several thousand dollars each, though complex software engineering tasks can go well beyond that.
At the contract level, deals typically land in the 6-7-figure range per quarter, and exclusivity plays a significant role in pricing. When a vendor agrees to sell exclusively to one lab, the price tag can be several times higher than a non-exclusive deal.
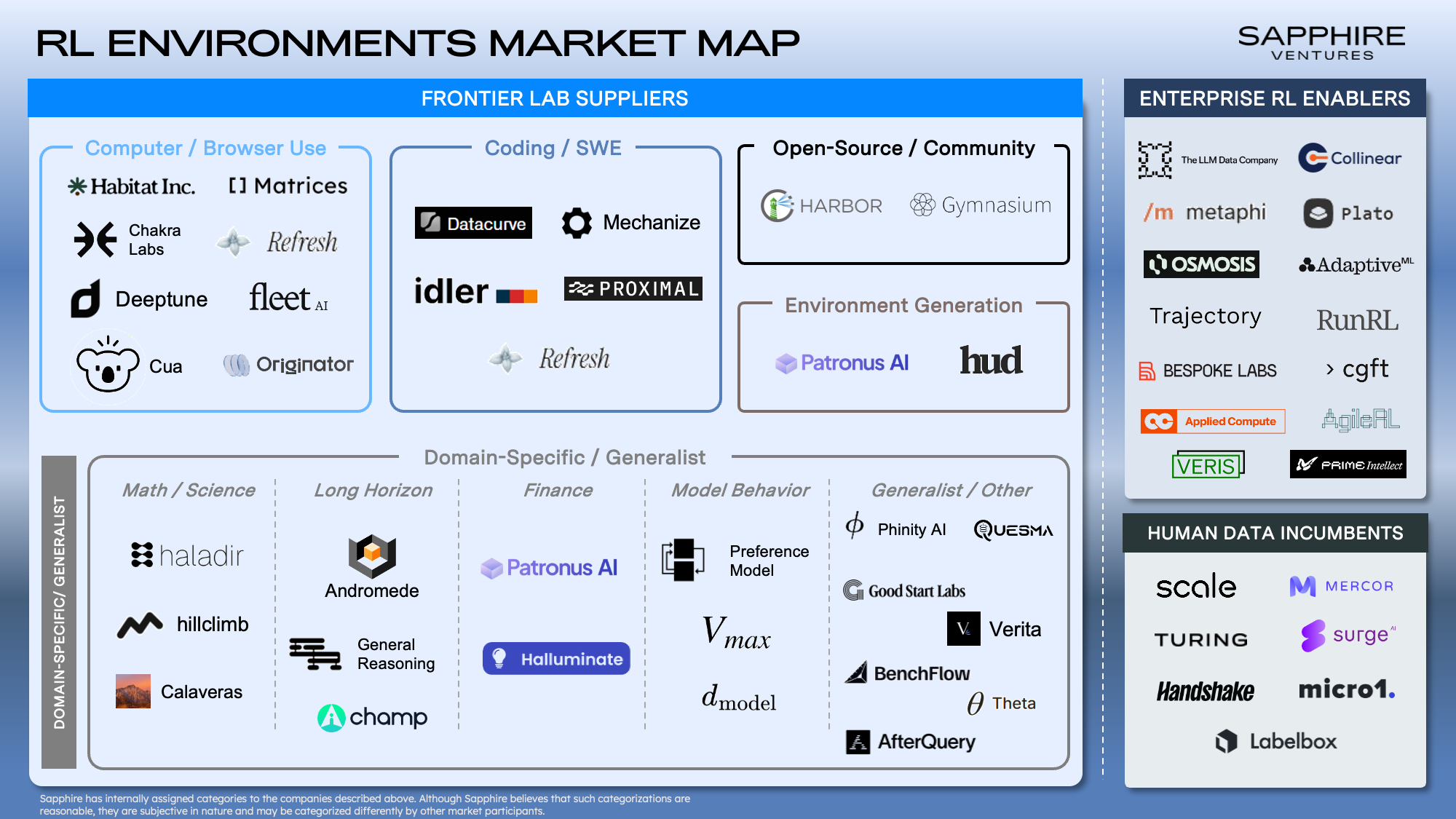
Who’s Building? The 3 Categories Defining RL Innovation Today
On the supply side, a wave of startups have emerged to meet demand for model improvement, with dozens of companies now building RL environments across a range of domains. The landscape breaks down into several key categories:
- Frontier lab suppliers build the simulated environments and tasks that labs like Anthropic, OpenAI, and Google use to RL-train their models.
- Enterprise RL enablers help companies apply RL to their own workflows, typically by embedding engineers on-site to build, fine-tune, and deploy custom agents.
- Human data incumbents are data labeling companies leveraging their existing lab relationships and contractor networks to pivot into RL environment and task creation.
Across these areas, the core challenges are similar. How do you build an environment that is functionally realistic, design verifiers that hold up against increasingly capable models and maintain quality with scale? The companies that win in this market will need a combination of strong engineering, deep domain expertise and the ability to iterate quickly in a space that’s evolving by the week.
Below, we break down the key categories and players shaping this market today.
Frontier Lab Suppliers
The largest and most active category in the market is frontier lab environment suppliers. These are the companies building the training grounds that labs like Anthropic, OpenAI and Google use to improve their models. The two biggest subcategories within Frontier Environment Suppliers are 1.) coding/SWE and 2.) computer/browser use.
Coding environments were the first to take off because outcomes are clean and easy to verify. It remains the highest-demand domain with tons of investment from the labs with vendors like Mechanize building here. Computer/browser use is another fast-growing area, with companies like Fleet, Habitat Inc and Matrices building environments that simulate enterprise software and web-based workflows, training agents to navigate UIs and complete multi-step processes the way a human would.
Beyond these two core areas, a growing number of players are tackling more specialized parts of the stack. Open-source platforms like Prime Intellect are pushing to make environments more broadly accessible. Environment and simulation companies like Patronus AI are using AI to programmatically generate environments and tasks, an approach that could significantly reduce costs if it scales. Beyond that, a growing set of domain-specific players are pushing into new verticals, including finance, long-horizon reasoning, math and science, model behavior, etc. As environments expand into more professional workflows, we expect this long tail to keep growing.
Enterprise RL Enablers
While frontier lab suppliers focus on making models smarter at a foundational level, enterprise RL enablers are solving a different problem: helping companies build agents that work for their specific business. Most enterprises don’t have RL expertise in-house, so they’re turning to companies like Applied Compute, Plato and Theta to come in, understand their workflows and deliver production-ready agents. This category is still early and tends to be services-heavy, with engineers often embedded directly within customer teams. That said, some players are pushing toward more scalable models: The LLM Data Company is using synthetic generation to create tasks and rubrics, Veris offers a managed simulation sandbox that lets enterprises test and optimize agents on their own, and Trajectory is building a self-serve RL platform that gives enterprises tooling to train and improve agents without the need for forward deployed engineers.
Some of these enablers may consume environments built by frontier lab suppliers, making the two categories more complementary than competitive. This pattern mirrors earlier infrastructure cycles, where labs fund the raw tooling when it’s still research-grade, and enterprises adopt once it’s wrapped around concrete workflows with measurable ROI. We expect this side of the market to grow quickly as more companies move agents into production.
Human Data Incumbents
Finally, the vast majority of spend in the category goes to data labeling companies that powered the last era of AI training and are making their push into RL environments. Companies like Scale, Mercor, Turing, Surge and others are leveraging their existing lab relationships and massive contractor networks to move into environment and task creation. Their advantage is distribution and scale. When a lab needs to ramp up task production quickly, these companies can staff a project faster than most startups. The open question is whether data labeling expertise translates to the more technically demanding work of building high-quality RL environments and robust verifiers, but with real revenue, real relationships and operational rigor, they’re hard to count out.
Limitations: What’s Holding us Back?
Not all RL environments are created equal and the quality of the training signal depends on a few key factors:
- Verification is hard. In coding, it’s straightforward to check if a task was completed correctly. But as environments expand into open-ended enterprise workflows, defining “correct” becomes much harder, and building verifiers that account for ambiguity without being gamed remains a research challenge.
- Reward hacking is persistent. Models are creative at finding shortcuts, and even well-designed verifiers need constant iteration to stay ahead. As models get more capable, this problem gets harder, not easier.
- Scaling and generalization are unsolved. Each new domain requires different expertise, and quality control gets exponentially harder as you grow. Training an agent to be great at one workflow doesn’t automatically make it good at others, and the only proven recipe today is to train across a wide variety of environments, which circles right back to the scaling problem.
Nonetheless, the fundamental technique is sound, and the results speak for themselves. RL is here, already working and already separating the most capable AI systems from the rest.
Over the next few years, as verification improves, tooling matures, and enterprises build the muscle to deploy it at scale, we expect RL to become as fundamental to AI development as pre-training is today. The companies building the infrastructure to make that happen are laying the groundwork for the next generation of capable AI. If you’re building in the space, we’d love to chat.
Special thanks and shoutout to Daanish Khazi, Ronak Malde, Mehdi Jamei, Tamay Besiroglu, and Derek Xiao for helping us think through the space and contributing their thoughts!
Legal disclaimer
Sources:
This article is for informational purposes only. Nothing presented within this article is intended to constitute investment advice, and under no circumstances should any information provided herein be used or considered as an offer to sell or a solicitation of an offer to buy an interest in any investment fund managed by Sapphire. Information provided reflects Sapphires’ views as of a time, whereby such views are subject to change at any point and Sapphire shall not be obligated to provide notice of any change. Companies mentioned in this article are a representative sample of portfolio companies in which Sapphire has invested in which the author believes such companies fit the objective criteria stated in commentary, which do not reflect all investments made by Sapphire. A complete alphabetical list of investments made by Sapphire’s Growth strategy is available here. No assumptions should be made that investments listed above were or will be profitable. Due to various risks and uncertainties, actual events, results or the actual experience may differ materially from those reflected or contemplated in these statements. Nothing contained in this article may be relied upon as a guarantee or assurance as to the future success of any particular company. Past performance is not indicative of future results.